4.1.5. Définir une colonne de partitionnement pour les sources de données de type SQL (JDBC)
When the Tale of Data engine reads a dataset, it is divided into several subsets of rows. Each subset is called a partition (if you group all these subsets together, you get the original dataset).
This approach makes it possible to perform sub-calculations in parallel, and then aggregate the partial results to obtain the final result. This is what is known as Map/Reduce (Map = divide, Reduce = aggregate results).
For example, if you want to convert a column to uppercase in a dataset of 1 million rows, and you have 100 cores (a core is a single processing unit within a microprocessor that can execute instructions), the ideal solution is to split the dataset into 100 groups of 10,000 rows each.
Suppose it takes one second to convert a column to uppercase in a dataset of 10,000 rows. By performing the calculation in parallel (each core processing 10,000 rows), the total duration of the operation is 1 second (assuming, for simplicity, that we exclude the time needed to split and reassemble the dataset).
Note
If we had performed this calculation sequentially on 1 million rows, it would have taken 100 seconds, i.e., 1 minute and 40 seconds.
The Tale of Data engine can automatically partition files (CSV, Parquet, …). However, when it comes to a relational database, the JDBC drivers load the data sequentially using a single execution process (core), which can significantly slow down performance and potentially exhaust the server’s resources (especially memory).
The solution is therefore to read the entire table by executing multiple SQL queries in parallel, each of which returns a subset of the dataset (it is essential that these subsets are disjoint and that together they cover the full dataset, which is the very definition of a partition).
To achieve this with acceptable performance, we assume that the user knows their data well enough to choose the most appropriate partition column.
Suppose the column chosen by the user is named partitionColumn.
Based on this information, Tale of Data will automatically generate the SQL queries below and assign the subset of rows returned by each query to a given processor core. The number of partitions (10 in the example below) and the partition boundaries, which have a constant step (1000, 2000, …, 9000 in the example below), are calculated automatically by Tale of Data:
SELECT * FROM db.table WHERE partitionColumn <= 1000;
SELECT * FROM db.table WHERE partitionColumn > 1000 and partitionColumn <= 2000;
...
SELECT * FROM db.table WHERE partitionColumn >= 9000;
Warning
For comparisons with the interval boundaries to work, it is essential that the partitioning column is of type numeric or date (in the Tale of Data graphical interface, you will not be allowed to choose a column of any other type).
This approach can be very effective in terms of performance, provided that you carefully choose an efficient partitioning column.
Example of a poor choice for the partitioning column:

Choosing Column1 as the partitioning column leads to the creation of 2 extremely unbalanced partitions: the largest partition is almost the size of the original dataset, so the time savings from parallelization will be negligible (the total duration of the calculation being that of the calculation on the largest partition).
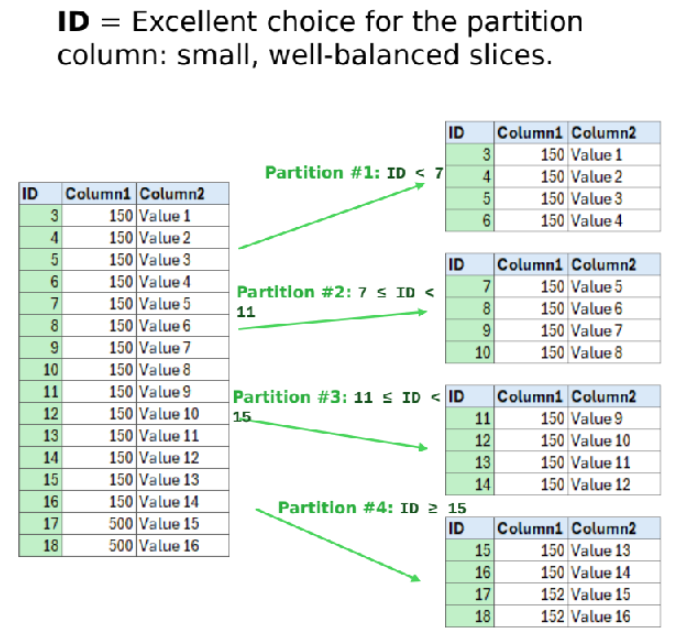
Example of a good choice for the partitioning column:
A good choice for the partitioning column is a numeric or date column with a value distribution that is as uniform as possible from the lower bound to the upper bound. In this sense, a database column of type auto-increment is often an ideal choice (provided that no very large blocks have been deleted).: