4.9. Enrichment node
If you want to learn more about this feature, an e-learning tutorial is available below:
Enrich your data using fuzzy logic
This video shows the use of custom fuzzy logic in the enrichment node of Tale of Data.
Custom fuzzy matching in the enrichment node
This video shows how to use the custom fuzzy matching tool in the enrichment node within Tale of Data. This allows, for example, to detect duplicates in your data, or to group data together based on approximate matching criteria. You can overcome common issues with manually entered data or data based on verbal information.
4.9.1. Description
Icon: 
Number of inputs: 2.
Number of outputs: 1.
- Definition
An enrichment node uses fuzzy matching to add new fields to a dataset (“enriched dataset* or dataset 1) from an enriching dataset (= dataset 2, connected by a blue link).
- Configuration
At input the enrichment node must be connected to precisely 2 nodes in the following order:
The enriched dataset: to which new fields are to be added.
The enriching dataset (connected by a blue link): this is the dataset that will contribute the new fields.
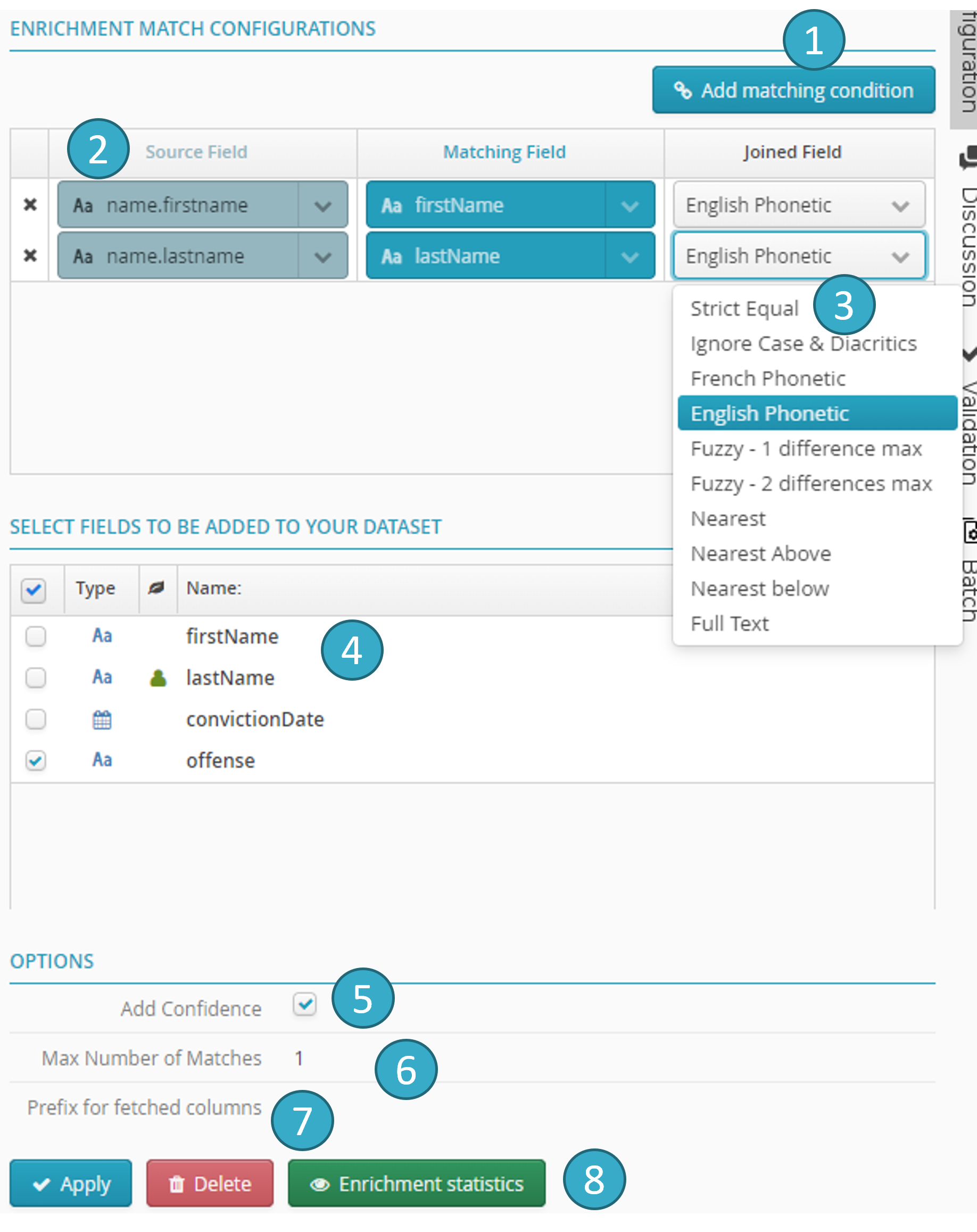
In the configurator, click Add a match condition
 to configure each match condition
to configure each match condition  for the enrichment.
for the enrichment.Match conditions are treated as a logical AND and must all be met.
Match options
 are:
are:Strict Equal:
the match will not be validated unless the values in the two matched cells are the same (the first cell must belong to the enriched dataset and the second to the enriching dataset).
Ignore Case & Diatrics:
the match will not be validated unless the values in the two matched cells are the same, apart from upper/lower case and accented character differences (both matched fields must be text type).
French Phonetics:
the match will not be validated unless the values in the two matched cells are pronounced identically in French (both matched fields must be text type).
English Phonetics:
the match will not be validated unless the values in the two matched cells are pronounced identically in English (both matched fields must be text type).
Fuzzy – 1 Difference Max:
the match will not be validated unless the values in the two matched cells have a Levenshtein [1] distance below or equal to 1 (both matched fields must be text type).
Fuzzy – 2 Differences Max :
the match will not be validated unless the values in the two matched cells have a Levenshtein distance below or equal to 2 (both matched fields must be text type).
Fuzzy - customized :
This match type allows you to specify the cost of the operations to be performed to match a string in the dataset to be enriched with a character string in the enrichment dataset (blue incoming link):
Cost for deletion: if this cost is set to 0.3, the distance between “abcd” and “ab” will be 0.6 (= 2 deletions x 0.3).
Cost for insertion: if this cost is set to 0.8, the distance between “abd” and “abcd” will be 0.8 (= 1 insertion x 0.8).
Cost for changing (substitution of one character by another): if this cost is set to 0.9, the distance between “abcd” and “abzd” will be 0.9 (= 1 change x 0.9).
Cost for switching (permutation of two adjacent characters): if this cost is set to 0.5, the distance between “abca” and “acba” will be 0.5 (= 1 switch x 0.5).
Maximum total cost for matching: there will be a match only if the sum of the costs of the operations to be performed on the characters is less than or equal to this cost. Warning: if the maximum total cost for matching is less than the least expensive operation, only identical character strings will be accepted.
Warning
Character operations will be performed in such a way as to minimize the total cost (e.g. if deletion plus insertion is “cheaper” than change, the cost of change, i.e. the substitution of one character for another, will never be applied).
Nearest:
this condition, which cannot be used alone, allows two enriching dataset records to be shared so long as the other matching conditions have been met. Priority will be given to the one closest to the values in the two matched cells (both matched columns must be continuous type, either numeric or date).
Note
To use this function, you need a “strict equals” condition first. The “nearest” condition is applied second. The idea is that the strict equals condition limits the number of rows to compare to around a dozen (a small amount), so that the feature can operate efficiently at scale.
Full text:
this condition only makes sense when both matched cells contain several words (usually a short text). The match algorithm will match a cell in the enriched dataset with the cell in the enriching dataset that shares the largest number of words with it (both matched fields must be text fields).
Select at least one field in the enriching dataset that is to be retrieved in the enriched dataset
 .
.Three additional settings are available when configuring an enrichment node:
The confidence score
 measures the reliability of a fuzzy join.
measures the reliability of a fuzzy join.This ranges from 0 (= unreliable join because of major differences between the joined fields) to 1 (= very reliable join because all joined fields are identical).
Max number of matches
 :
:this is the max number of enriching dataset records matched with an enriched dataset record. For example, if assigned a value of 3, one enriched dataset record can create up to 3 matched records in the result dataset so that the 3 best matches found can be kept.
Prefix for retrieved columns
 :
:this option lets you specify a prefix text for all the new columns retrieved after enrichment.
At the bottom of the enrichment node configurator, click Enrichment Statistics
 for information on data enrichment performance.
for information on data enrichment performance.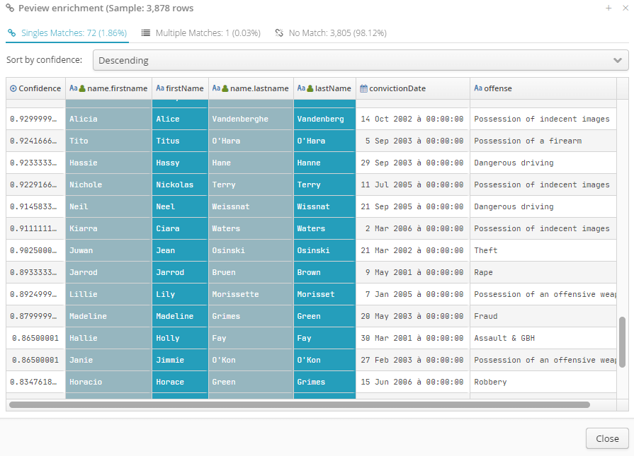
The 3 tabs show a sample of enriched dataset records that have one, multiple or no match(es) in the enriching dataset.
Color code:
 enriched dataset field.
enriched dataset field. enriching dataset field.
enriching dataset field.
Tip
If your enriching dataset is big (several hundred thousand to several hundred million records), use Tale of Data repositories rather than an enrichment node.
- Visual Example
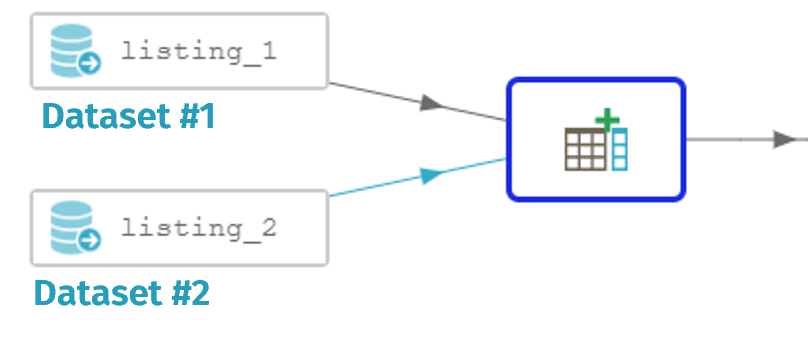
In this example, dataset 1 is enriched by dataset 2.
The first record in the table above shows that Jacky Hubert was matched with Jackie Hubert (phonetic match) and that the similarity ratio is 0.8933 (because of the different spellings of Jacky and Jackie).
- Practical examples
Note
Example 1: Enriching Customer Data with English Phonetic Matching
Before Operation :
Dataset 1 (Enriched Dataset - Products)
Customer ID
Customer Name
Country
001
John Doe
USA
002
Jane Smith
Canada
Dataset 2 (Enriching Dataset - Reviews):
Order ID
Full Name
Order Amount
Review Date
O001
John Doe
100
2023-03-01
R002
Jane Smith
200
2023-02-01
Node Configuration:
Fuzzy – 2 Differences Max :
Match Condition: Match “Product Name” from Dataset 1 with “Reviewed Product” from Dataset 2
Fields to Enrich: Add “Review ID”, “Rating”, “Review Date” to Dataset 1
After Operation:
Enriched Dataset (Products with Reviews) :
Customer ID
Customer Name
Country
Order ID
Order Amount
Review Date
001
John Doe
USA
O001
100
2023-03-01
002
Jane Smith
Canada
R002
200
2023-02-01
Note
Example 2: Enriching Product Listings Using Fuzzy Matching (Levenshtein Distance 2)
Before Operation :
Dataset 1 (Enriched Dataset - Products)
Product ID
Product Name
Price
P001
Portable Speaker
50
P002
Wireless Earbuds
70
Dataset 2 (Enriching Dataset - Reviews):
Review ID
Reviewed Product
Rating
Review Date
R001
Portable Speeker
4.5
2023-03-01
R002
Wireless Earbudz
4.7
2023-03-02
Node Configuration:
Fuzzy – 2 Differences Max :
Match Condition: Match “Product Name” from Dataset 1 with “Reviewed Product” from Dataset 2
Fuzzy Matching Parameters: Maximum Differences = 2
Fields to Enrich: Add “Review ID”, “Rating”, “Review Date” to Dataset 1
After Operation:
Enriched Dataset (Products with Reviews) :
Product ID
Product Name
Price
Review ID
Rating
Review Date
P001
Portable Speaker
50
R001
4.5
2023-03-01
P002
Wireless Earbuds
70
R002
4.7
2023-03-02