10. Tale of Data repositories
10.1. What are indexed repositories?
Repositories allow you to repair or enrich datasets by leveraging advanced matching algorithms.
They are reusable datasets that are indexed to enable extremely fast searches. Thanks to this indexing, repositories can be used to compare, correct, or enrich data using different types of matching strategies, including:
Full-text: perform searches that tolerate subsets of words within a field (maximizing the number of words in common with the searched text, weighted by Inverse Document Frequency).
Fuzzy: introduce tolerance for typos and minor spelling variations.
Phonetic (French / English): search for terms with a similar pronunciation.
Note
Exact matching is, of course, also supported.
Users can create their own repositories (products, companies, people, services, locations, etc.). These repositories can be intended for private use, for use within a specific collaborative space, or shared with all users of the platform as official repositories.
A repository is created using a flow, by leveraging a dedicated target: the repository node.
10.2. Use cases – how and why repositories are used
The user works with a working data table containing information that needs to be matched against a repository, whether private or shared within the company, and previously computed.
This matching is performed using the preparation editor. The user will typically:
select the repository to use from those available in their catalog;
choose which matching tools provided by the repository should be applied;
associate these matching tools with one or more columns from the working data;
define how many repository results should be returned in case of a positive match;
select which repository columns should be brought back into the working data.
Once the working data has been matched with the repository data, it becomes possible to implement:
controls and validations to identify whether data is compliant with the repository;
enrichment mechanisms to correct and enhance the working data using the “official” data from the selected repository.
On most Tale of Data platforms, official repositories are provided. These are most often national company databases, when they are published as open data. Such repositories can be used, for example, to clean up company lists: detecting address changes, refining the official company name, or identifying companies that have ceased operations.
Note
At a global scale, the LEI (Legal Entity Identifier) database provides unique identifiers as well as name and address information for companies worldwide. A similar matching process can be performed by aligning names, countries, and address data between the working data and the indexed repository using fuzzy matching. This makes it possible, for example, to retrieve LEI numbers for most companies in the working data, enrich them with this identifier, or verify that they still exist and have not relocated.
Note
These examples are not exhaustive: repositories can be created for any type of data, as long as there is an intention to reuse them later on working datasets.
The following sections describe how a user can create an indexed repository from a table, whether for private use, within a collaborative space, or for shared use by all users within their company who have access to the Tale of Data platform. They also explain how to apply an existing repository to working data using the preparation editor.
10.3. Creating a repository
To create a repository you must create a flow.
A flow containing a repository can contain all the standard processors needed to prepare repository data but can only contain one repository processor that is a particular type of sink  .
.
Repository processors let you create a repository that can be reused and shared to reconcile data.
Example of a flow creating a repository:

10.3.1. Configuring an indexed repository
The name of the repository must be entered in the processor configurator.
A description is optional but is strongly advised because all repository users will be able to see it.
Repositories have three view levels:
Public.
Shared with my organization.
Private.
10.3.2. Search fields
These fields let repository users reconcile their data so it is important when creating a repository to select your search fields carefully.
For example, in a repository of persons, name will naturally be a search field.
To add a search field, click Add a search column  in the repository node configurator.
in the repository node configurator.
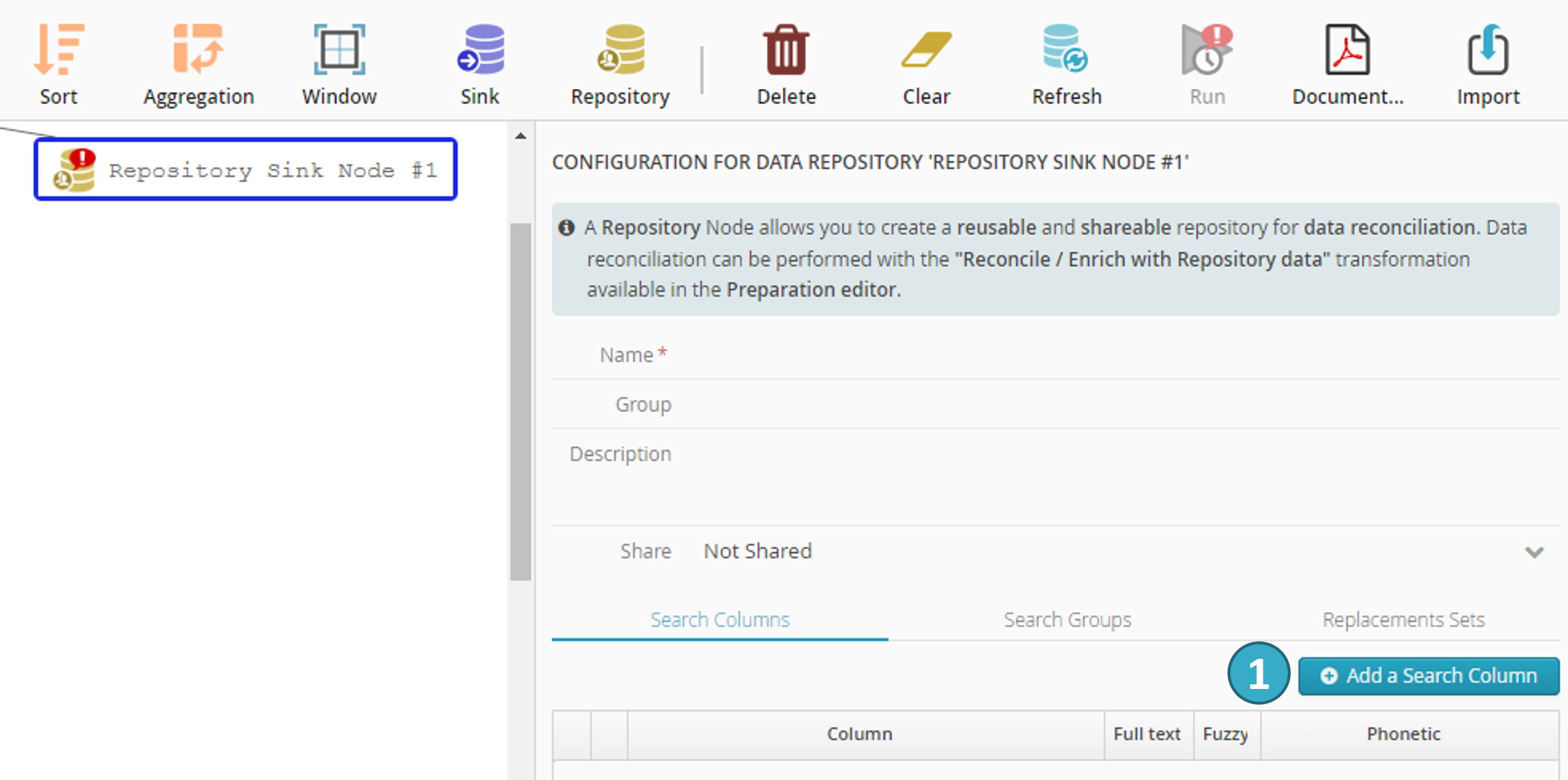
You can configure the search field in the dialogue window that opens:
You must specify the search field (postcode in the example above).
Full text lets you specify whether searches will accept a subset of words in the field.
Fuzzy lets you specify whether typos to be tolerated.
Phonetics lets you specify whether you want searches for words with similar pronunciations (3 options):
French.
English.
No phonetics.
Note
In Tale of Data, the similarity score is a value between 0 and 1 that measures how closely a piece of data matches an entry in the reference dataset. The calculation depends on the configured search type, with two main cases: search on a single column or on a group of columns.
Case 1: search on a single column
When a search column is used without enabling any specific option, the result is an exact match:
identical value → score = 1
- different value → score = 0
This is for example the case for fields such as a department.
If the fuzzy option is enabled without checking full text, similarity is calculated using the Jaro-Winkler distance.
In practice, this makes it possible to handle small spelling variations while giving more weight to the first letters.
For example, “Guillaume” and “Guilaume” will have a high score, whereas “Jillaume” and “Guillaume” will be more heavily penalized because the difference is at the beginning of the word.
If you want to explore the calculation in more detail, you can consult it at any time in the following wiki.
As soon as the full text option is checked on a column, the string is no longer compared as a single block: the comparison switches to a token-based similarity.
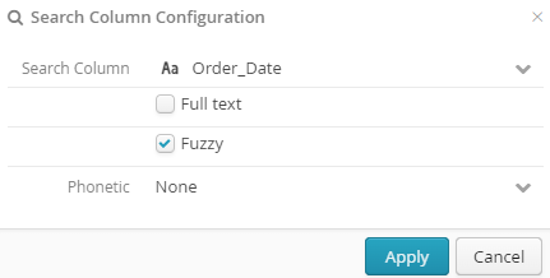
10.3.3. Search groups
Search groups let repository users search for matches between one field in their own dataset and several repository fields. This is useful if, for example, you have a dataset containing a full name (= first name + surname) and want to search for matches in a repository that stores first names and surnames as two separate fields.
In the Create a group search window you can enter the name of the group, its description and its fields. Fuzzy and phonetics options are also available (see Search fields for an explanation of both concepts).
Note
In Tale of Data, the similarity score is a value between 0 and 1 that measures how closely a piece of data matches an entry in the reference dataset. The calculation depends on the configured search type, with two main cases: search on a single column or on a group of columns.
Case 2: search on a group of columns
When a search group is defined (multiple combined columns), Tale of Data always uses a token-based similarity.
The principle is to compare two sets of words and measure their overlap.
For example, between “hello sir” and “hello madam”, the intersection is the word “hello”, while the union is “hello”, “sir”, and “madam”.
The similarity is therefore 1 word in common out of 3, i.e. 1/3.
Finally, the global score returned by the reference dataset is the average of the scores calculated for each search criterion (configured columns and/or groups).
10.3.4. Lists of replacements
These let you configure the word replacements you want to use when reconciling or enriching data.
For example, you can specify that if the word ‘car’ appears in your dataset it must trigger a search for the word ‘vehicle’ in the repository. To do this, just add the following row to the list of replacements:
“car;vehicle”.
Note
Replacements can only be made for whole words (separated from other words). ‘;’ (semi-colon) can be used only to separate text to be replaced from its replacement text.
Replacements are upper/lower case insensitive.
You can specify regular expressions [3] for replacements by starting your row with \x.
Example: \x(?i)(\d+)(?:B|BIS)\b;$1 bis will change the search request 3b rue de la Gare to 3 bis rue de la Gare.
Caution
To create the repository, you must run the flow.
You can view the repositories that are available in the catalog:
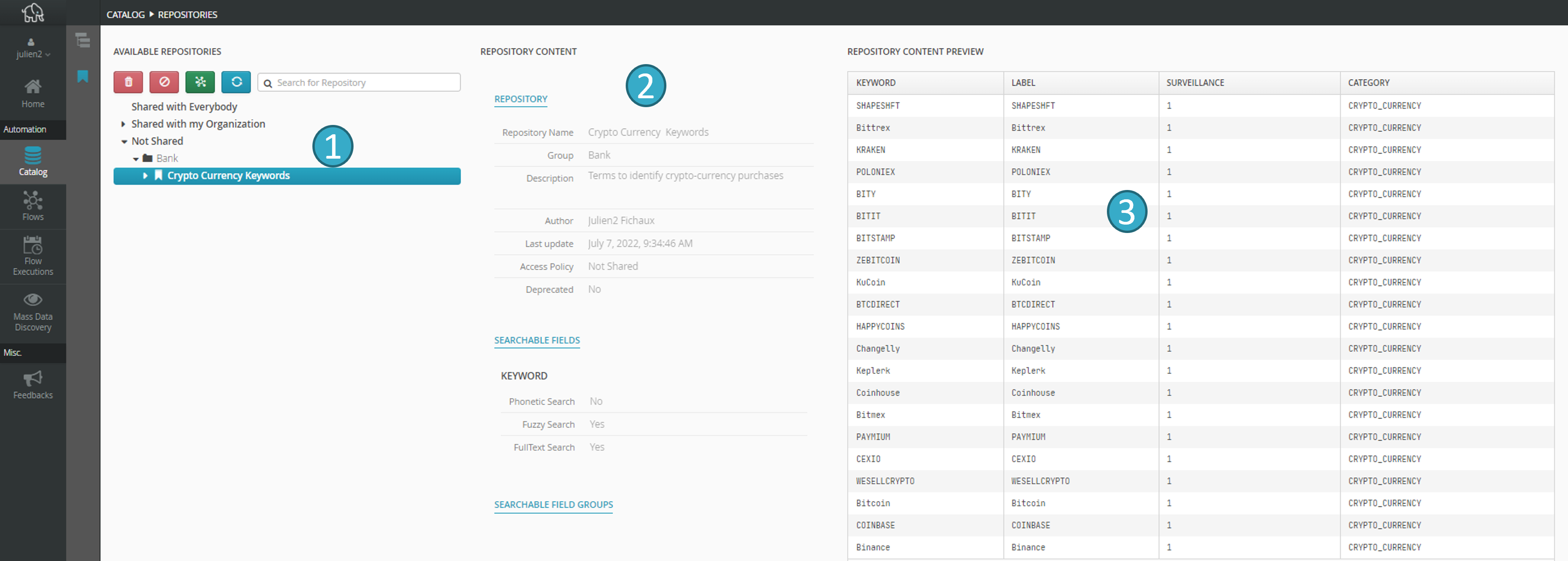
In the following main zones:
Zone for browsing
and selecting repositories.
Information zone
of the selected repository.
Preview zone
for repository data.
10.4. Using repositories
To reconcile data, use the Reconcile / Enrich with repository data transformation in the preparation editor:
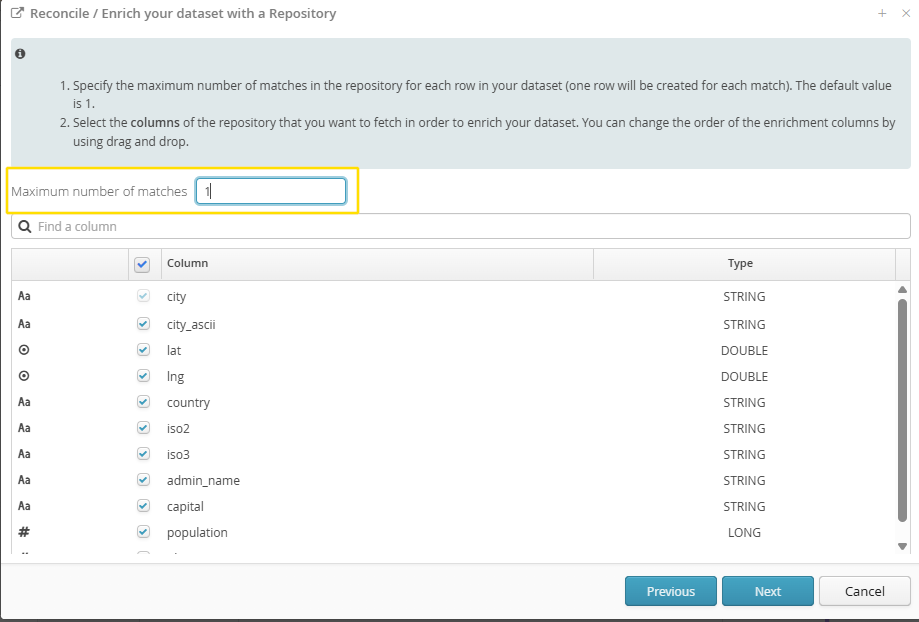
A wizard will configure the transformation and let you choose:
The repository with which you want to reconcile your dataset.
The matches between the fields in your dataset and the repository search fields (or groups).
The repository fields with which you want to enrich your dataset (you can choose a field subset and then reorder the fields using drag and drop).
Hint
It is possible, by setting a maximum number of matches greater than 1, to obtain a set of possible matches found during the application of the reference dataset.
Thus, if the limit is kept at 1, Tale of Data will suggest the best possible match. If this limit is increased and multiple possible matches are found, they will all be returned, up to the defined maximum number.
Note
Practical example : Reconcile / Enrich with Repository data
Before Transformation:
CustomerID |
Name |
|
|---|---|---|
1 |
John Doe |
|
2 |
Jane Smith |
Transformation Configuration:
Repository: “Account repository”
Reconciliation Model:
Match Name column from your dataset with Name column from Account repository. Match strategy:
Fuzzy Match(We’d like to avoid missing matches due to spelling mistakes on the name).
Fetched Columns:
ProfileID,AccountStatusMatch Count: 1 (only the best match is fetched)
After Transformation:
CustomerID |
Name |
ProfileID |
AccountStatus |
|
|---|---|---|---|---|
1 |
John Doe |
101 |
Active |
|
2 |
Jane Smith |
204 |
Inactive |
In this example, the transformation enriches the original dataset by adding ProfileID and AccountStatus from the Account repository based on the best match found for each customer name.