4.1.5. Définir une colonne de partitionnement pour les sources de données de type SQL (JDBC)
Lorsque le moteur de Tale of Data lit un jeu de données, ce dernier est divisé en plusieurs sous-ensembles de lignes. Chaque sous-ensemble est appelé une partition (si l’on regroupe tous ces sous-ensembles on obtient le jeu de données de départ).
Cette approche permet d’effectuer des sous calculs en parallèle, puis d’agréger les résultats partiels pour obtenir le résultat final. C’est ce qu’on appelle le Map/Reduce (Map = diviser, Reduce = Regrouper les résultats).
Par exemple si l’on veut mettre une colonne en majuscule dans un jeu de données de 1 million de lignes, et que l’on dispose de 100 cœurs (un cœur est une unité de traitement unique au sein d’un microprocesseur qui peut exécuter des instructions), l’idéal est de diviser le jeu de données en 100 groupes de 10 000 lignes chacun.
Supposons qu’il faille une seconde pour mettre une colonne en majuscule sur un jeu de données de 10 000 lignes. En effectuant le calcul en parallèle (chaque cœurs traitant 10000 lignes), la durée totale de l’opération est de 1 seconde (si, pour simplifier, on exclut le temps de division et de réassemblage du jeu de données).
Note
Si on avait effectué ce calcul séquentiellement sur 1 million de lignes, cela aurait pris 100 secondes, soit 1 minute et 40 secondes.
Le moteur de Tale of Data est capable de partitionner automatiquement les fichiers (CSV, parquet…), en revanche lorsqu’il s’agit d’une base de données relationnelle, les drivers (JDBC) chargent les données de manière séquentielle à l’aide d’un seul processus (cœur) d’exécution, ce qui peut ralentir considérablement les performances et potentiellement épuiser les ressources du serveur (notamment la mémoire).
La solution est donc de lire la totalité de la table en exécutant en parallèle plusieurs requêtes SQL dont chacune retourne un sous-ensemble du jeu de données (il est indispensable que ces sous-ensembles soient disjoints et que la totalité des sous-ensembles soit le jeu de données, ce qui est la définition même d’une partition).
Pour réussir à faire cela avec des performances acceptables, on part de l’idée que l’utilisateur connaît suffisamment ses données pour choisir la meilleure colonne de partition possible.
Supposons que la colonne choisie par l’utilisateur se nomme partitionColumn.
À partir de cette information Tale of Data va automatiquement générer les requêtes SQL ci-dessous et assigner le sous-ensemble de lignes retourné par chaque requête à un cœur de processeur donné. Le nombre de partitions (10 dans l’exemple ci-dessous) et les bornes des partitions, qui ont un pas constant (1000 , 2000,…, 9000 dans l’exemple ci-dessous) sont calculés automatiquement par Tale of Data :
SELECT * FROM db.table WHERE partitionColumn <= 1000;
SELECT * FROM db.table WHERE partitionColumn > 1000 and partitionColumn <= 2000;
...
SELECT * FROM db.table WHERE partitionColumn >= 9000;
Avertissement
Afin que les comparaisons avec les bornes d’intervalles fonctionnent, il est indispensable que la colonne de partitionnement soit de type numérique ou date (au niveau de l’interface graphique Tale of Data ne vous permettra pas de choisir une colonne d’un autre type).
Cette approche peut être très efficace en termes de performance à condition de choisir judicieusement une colonne de partitionnement performante.
Exemple de mauvais choix pour la colonne de partitionnement :

Le choix de Column1 comme colonne de partitionnement conduit à la création de 2 partitions extrêmement déséquilibrées : la plus grosse partition ayant presque la taille du jeu de données initial, le gain de temps de la parallélisation sera négligeable (la durée totale du calcul étant la durée du calcul sur la plus grosse partition).
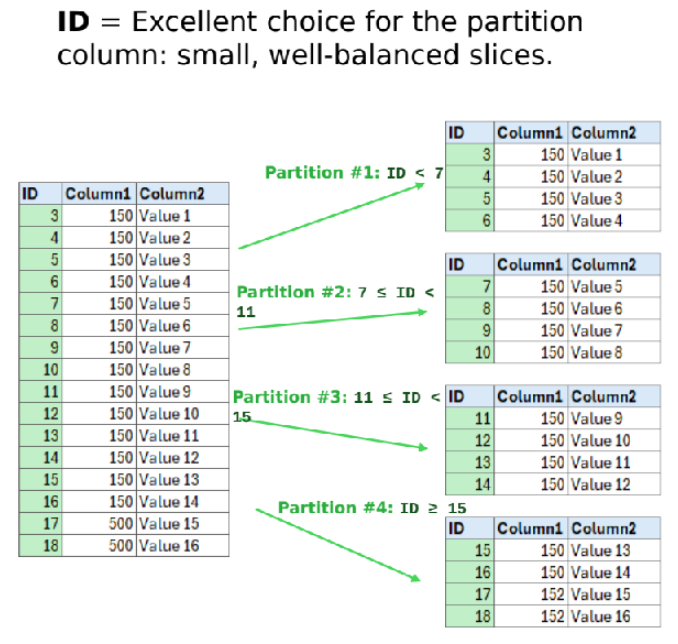
Exemple de bon choix pour la colonne de partitionnement :
Un bon choix de colonnes de partition est celui d’une colonne de type numérique ou date avec une distribution de valeur qui soit le plus uniforme possible de la borne inférieure à la borne supérieure. En ce sens une colonne de base de données de type auto-incrément est souvent un choix idéal (sous réserve qu’il n’y ait pas eu de trop gros blocs supprimés)