10. Les référentiels dans Tale of Data
10.1. Que sont les référentiels indexés ?
Les référentiels permettent de réparer ou d’enrichir des jeux de données en s’appuyant sur des algorithmes de matching avancés.
Il s’agit de jeux de données réutilisables, indexés afin de permettre des recherches extrêmement rapides. Grâce à cette indexation, ils peuvent être utilisés pour comparer, corriger ou enrichir des données à l’aide de différents types de correspondances, parmi lesquels :
Texte intégral : effectuer des recherches tolérant des sous-ensembles de mots dans un champ (maximisation du nombre de mots en commun avec le texte recherché, pondération par Inverse Document Frequency).
Flou : introduire une tolérance aux fautes de frappe et aux variations mineures d’écriture.
Phonétique (français / anglais) : rechercher des termes ayant une prononciation similaire.
Note
Il est bien entendu également possible d’effectuer des correspondances exactes.
Les utilisateurs peuvent créer leurs propres référentiels (produits, sociétés, personnes, services, lieux, etc.). Ces référentiels peuvent être destinés à un usage privé, à l’intérieur d’un espace collaboratif spécifique, ou être partagés avec l’ensemble des utilisateurs de la plateforme en tant que référentiels officiels.
La création d’un référentiel s’effectue à l’aide d’un flow, en utilisant une cible dédiée : le nœud référentiel.
10.2. Cas d’usages - comment et à quoi servent les référentiels
L’utilisateur dispose d’une table de données de travail, contenant des informations qu’il souhaite rapprocher d’un référentiel, qu’il soit privé ou partagé au sein de l’entreprise, et préalablement calculé.
Ce rapprochement s’effectue à l’aide de l’éditeur de préparation. L’utilisateur va notamment :
sélectionner le référentiel à utiliser parmi ceux disponibles dans son catalogue ;
choisir les outils de rapprochement proposés par le référentiel à mobiliser ;
associer ces outils de rapprochement à une ou plusieurs colonnes de la donnée de travail ;
définir le nombre de résultats du référentiel à rapatrier en cas de correspondance positive ;
sélectionner les colonnes du référentiel à intégrer dans la donnée de travail.
Une fois la donnée de travail rapprochée de la donnée référentielle, il devient possible de mettre en place :
des contrôles et validations afin d’identifier les données conformes ou non par rapport au référentiel ;
des mécanismes d’enrichissement permettant de corriger et de compléter la donnée de travail à l’aide de la donnée « officielle » issue du référentiel sélectionné.
Sur la plupart des plateformes Tale of Data, des référentiels officiels sont fournis. Il s’agit le plus souvent de bases de données nationales d’entreprises, lorsqu’elles sont publiées en open data. Ces référentiels peuvent par exemple être utilisés pour redresser des listes d’entreprises : détecter un changement d’adresse, affiner le nom retenu pour une société, ou encore identifier des entreprises ayant cessé leur activité.
Note
À l’échelle internationale, la base de données LEI (Legal Entity Identifier) fournit des identifiants uniques ainsi que des informations de nom et d’adresse pour des entreprises du monde entier. Un rapprochement similaire peut être réalisé en faisant correspondre les noms, pays et adresses entre la donnée de travail et le référentiel indexé, à l’aide de matching flou. Cela permet, par exemple, de récupérer les numéros LEI pour la majorité des entreprises présentes dans la donnée de travail, de les enrichir avec cet identifiant, ou de vérifier qu’elles existent toujours et n’ont pas changé de localisation.
Note
Ces exemples ne sont toutefois pas exhaustifs : il est possible de constituer des référentiels sur tout type de données, dès lors qu’il existe un besoin de réutilisation ultérieure sur des données de travail.
Les sections suivantes détaillent la manière dont un utilisateur peut créer un référentiel indexé à partir d’une table, que ce soit pour un usage privé, au sein d’un espace collaboratif, ou pour un usage partagé avec l’ensemble des utilisateurs de son entreprise disposant d’un accès à la plateforme Tale of Data. Elles expliquent également comment exploiter un référentiel existant sur de la donnée de travail à l’aide de l’éditeur de préparation.
10.3. Création d’un référentiel
La création d’un référentiel nécessite de créer un flow.
Le flow contenant un référentiel peut contenir tous les processeurs habituels pour préparer les données du référentiel, mais il ne peut contenir qu’un seul processeur de type référentiel qui est une cible particulière  .
.
Un processeur de type référentiel permet de créer un référentiel réutilisable et partageable pour la réconciliation de données.
Exemple de flow créant un référentiel :

10.3.1. Configuration du référentiel indexé
Le nom du référentiel doit être spécifié dans le configurateur du processeur.
La description est optionnelle, mais fortement conseillée car elle sera visible par les utilisateurs du référentiel.
Les référentiels ont trois niveaux de visibilité possibles :
Public.
Partagé avec mon organisation.
Privé.
10.3.2. Champs de recherche
Ce sont les champs qui permettront à l’utilisateur du référentiel de réconcilier ses données, il est donc important, lorsque l’on crée un référentiel, de bien choisir les champs de recherche.
Par exemple pour un référentiel de personnes, le nom est logiquement un champ de recherche.
Pour ajouter un champ de recherche, cliquer sur le bouton Ajouter une colonne de recherche  dans le configurateur du nœud Référentiel :
dans le configurateur du nœud Référentiel :
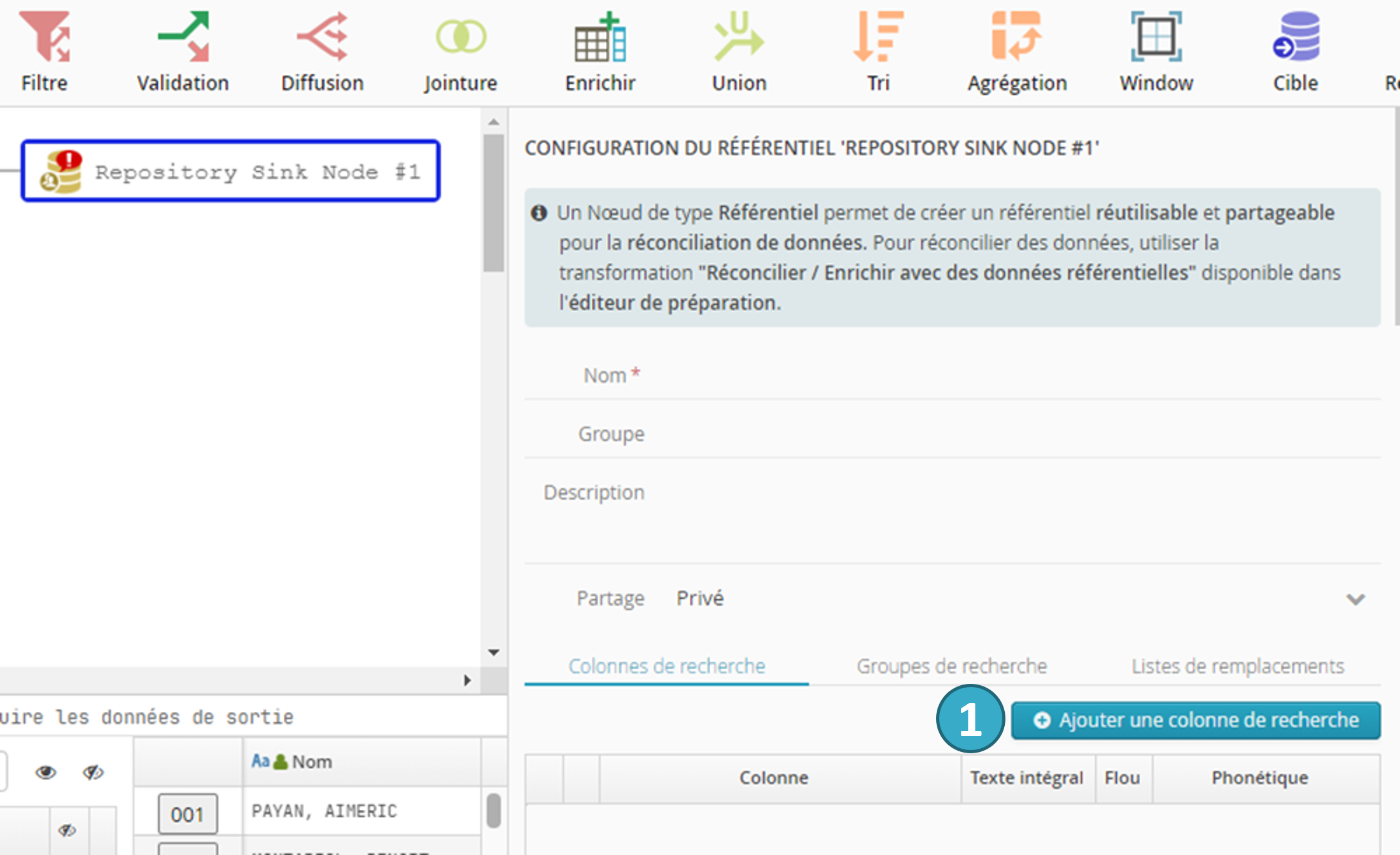
La fenêtre de dialogue qui s’ouvre permet de configurer le champ de recherche :
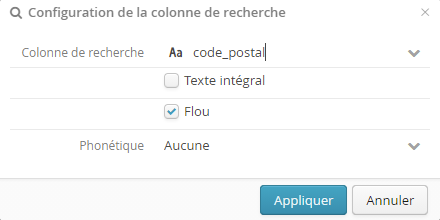
Il est nécessaire de spécifier le champ de recherche (code_postal dans l’exemple ci-dessus) :
L’option Texte intégral permet de préciser si l’on souhaite effectuer des recherches qui acceptent un sous-ensemble de mots du champ.
L’option Flou permet de préciser si l’on souhaite une tolérance aux fautes de frappe.
L’option Phonétique permet de préciser si l’on veut effectuer une recherche sur des mots ayant une prononciation similaire, 3 options sont disponibles :
Français.
Anglais.
Aucune phonétique.
Note
Dans Tale of Data, le score de similarité est une valeur entre 0 et 1 qui mesure à quel point une donnée correspond à une entrée du référentiel. Le calcul dépend du type de recherche configuré, avec deux cas principaux : recherche sur une colonne ou sur un groupe de colonnes.
Cas 1 : recherche sur une colonne
Lorsque l’on utilise une colonne de recherche sans activer d’option particulière, on est sur un match exact :
valeur identique → score = 1
- valeur différente → score = 0
C’est par exemple le cas pour des champs comme le département.
Si l’option flou est activée sans cocher texte intégral, la similarité est calculée avec la distance de Jaro-Winkler.
Concrètement, cela permet de gérer des petites variations d’écriture, tout en donnant plus d’importance aux premières lettres.
Par exemple, « Guillaume » et « Guilaume » auront un score élevé, alors que « Jillaume » et « Guillaume » seront plus pénalisés car la différence est au début du mot.
Si vous souhaitez voir plus en détail le calcul, vous pouvez à tout moment le consulter dans le wiki suivant.
Dès que l’option texte intégral est cochée sur une colonne, on ne compare plus la chaîne comme un seul bloc : on passe sur une similarité par tokens.
10.3.3. Groupes de recherche
Les groupes de recherche permettent à l’utilisateur d’un référentiel de chercher une correspondance entre un champ de son jeu de données et plusieurs champs du référentiel. Cela est, par exemple, utile si l’utilisateur a un jeu de données contenant un nom complet (= prénom + nom) et qu’il veut chercher des correspondances dans un référentiel qui, lui, stocke les prénoms et les noms de famille dans deux champs séparés.
La fenêtre de création d’un groupe de recherche permet de spécifier le nom du groupe, sa description et les champs qui le composent. Les options Flou et Phonétique sont également disponibles (cf. Champs de recherche pour l’explication de ces deux notions).
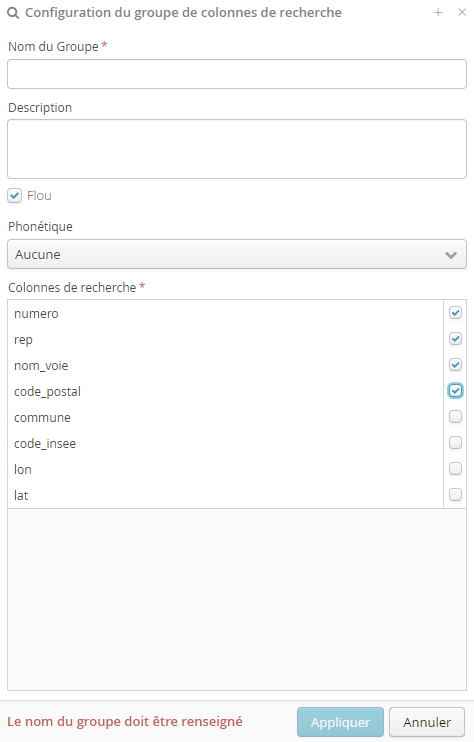
Note
Dans Tale of Data, le score de similarité est une valeur entre 0 et 1 qui mesure à quel point une donnée correspond à une entrée du référentiel. Le calcul dépend du type de recherche configuré, avec deux cas principaux : recherche sur une colonne ou sur un groupe de colonnes.
Cas 2 : recherche sur un groupe de colonnes
Lorsqu’on définit un groupe de recherche (plusieurs colonnes combinées), Tale of Data utilise toujours une similarité par tokens.
Le principe est de comparer deux ensembles de mots et de mesurer leur recouvrement.
Par exemple, entre « bonjour monsieur » et « bonjour madame », l’intersection est le mot « bonjour », tandis que l’union est « bonjour », « monsieur » et « madame ».
La similarité est alors de 1 mot en commun sur 3, soit 1/3.
Enfin, le score global retourné par le référentiel est la moyenne des scores calculés sur chaque critère de recherche (colonnes et/ou groupes configurés).
10.3.4. Listes de remplacement
Ces listes permettent de configurer les remplacements de mots que vous souhaitez utiliser pendant la réconciliation ou l’enrichissement de données.
Par exemple, vous pouvez indiquer que la présence du mot voiture dans votre jeu de données doit déclencher une recherche sur le mot véhicule dans le référentiel. Il vous suffit pour cela d’ajouter la ligne suivante dans la liste de remplacements :
« voiture;véhicule ».
Note
Les remplacements s’effectuent sur des mots entiers (donc isolés des autres mots). Le caractère “;” (point-virgule) est réservé à la séparation du texte à remplacer et du texte de remplacement.
Les remplacements sont insensibles à la casse (majuscule / minuscule).
Vous pouvez spécifier une expression régulière [3] pour les remplacements en commençant votre ligne par \x.
Exemple : \x(?i)(\d+)(?:B|BIS)\b;$1 bis transformera la requête de recherche 3b rue de la Gare en 3 bis rue de la Gare.
Prudence
Pour créer le référentiel, il est nécessaire d’exécuter le flow.
Les référentiels disponibles sont visibles depuis le Catalogue :
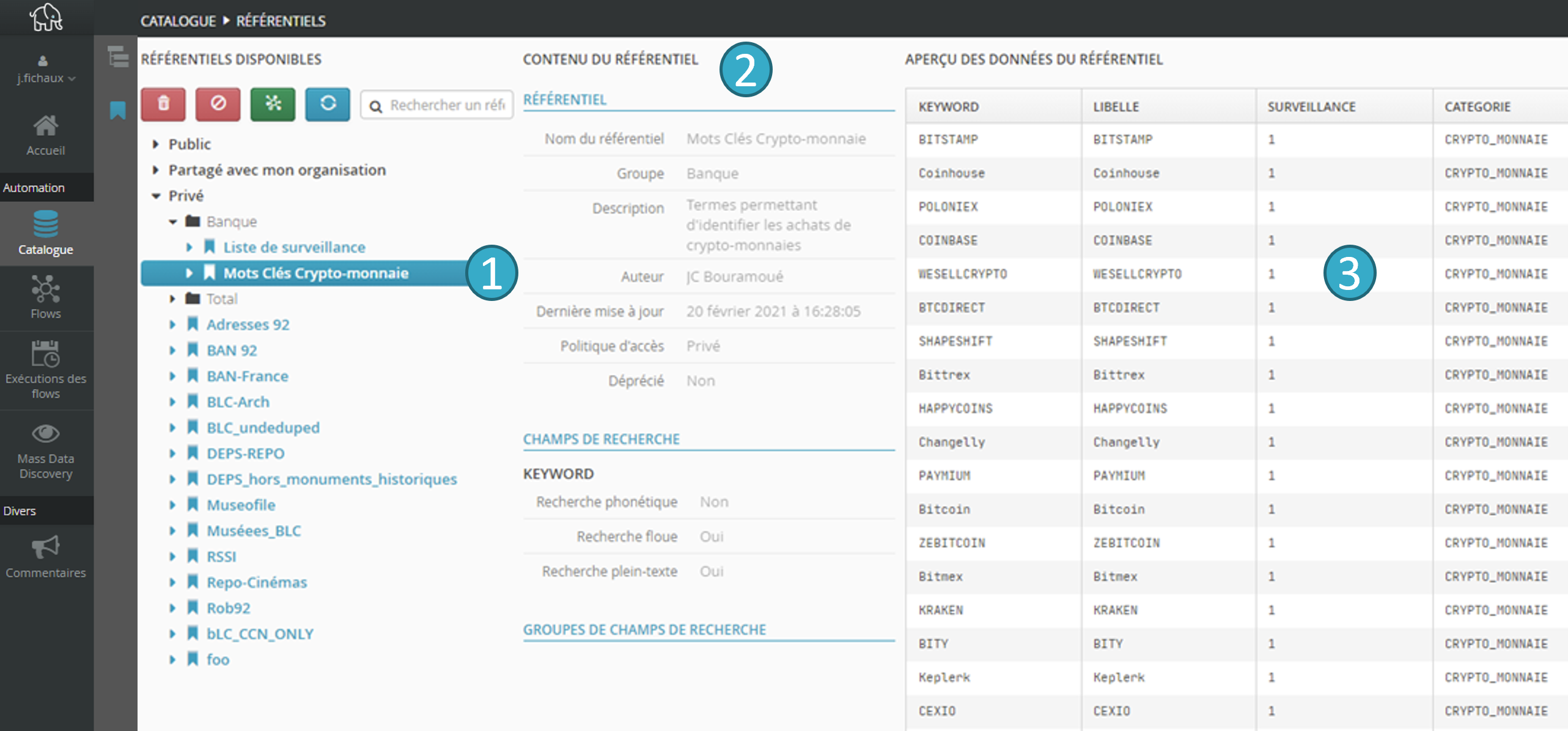
Avec les zones principales suivantes :
Zone de navigation
et de sélection des référentiels.
Zone d’information
du référentiel sélectionné.
Zone d’aperçu
des données du référentiel.
10.4. Utilisation des référentiels
Pour réconcilier des données, il faut utiliser la transformation Réconcilier / Enrichir avec des données référentielles disponible dans l’éditeur de préparation:
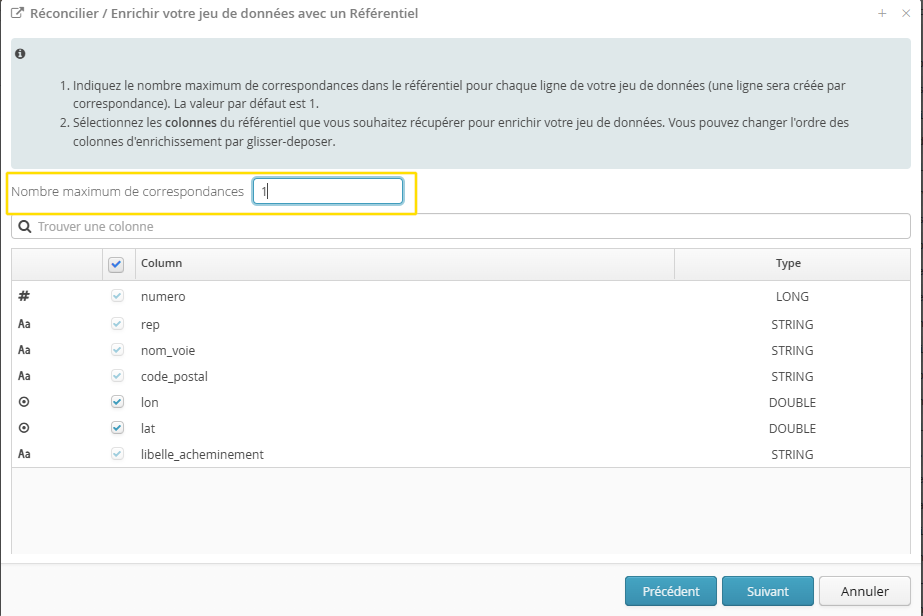
La transformation se configure avec un wizard, qui permet de choisir :
Le référentiel avec lequel on souhaite réconcilier son jeu de données.
Les correspondances entre les champs de mon jeu de données et les champs de recherche (ou les groupes de recherche) du référentiel.
Les champs du référentiel avec lesquels on souhaite enrichir son jeu de données (il est possible de choisir un sous-ensemble de champs et de réordonner les champs par glisser-déposer).
Indication
Il est possible, en paramétrant un nombre maximal de correspondances supérieur à 1, d’obtenir un assortiment de correspondances possibles trouvées lors de l’application du référentiel.
Ainsi, si l’on garde la limite à 1, Tale of Data proposera la meilleure correspondance possible. Si l’on augmente cette limite et que plusieurs correspondances possibles ont été trouvées, elles seront toutes remontées, dans la limite du nombre maximal défini.
Note
Exemple pratique : Réconcilier / Enrichir avec des données référentielles
Avant Transformation :
CustomerID |
Nom |
|
|---|---|---|
1 |
John Doe |
|
2 |
Jane Smith |
Configuration de Transformation :
Référentiel : « Référentiel des Comptes »
Modèle de Rapprochement :
Faire correspondre la colonne Nom de votre jeu de données avec la colonne Nom du Référentiel des Comptes. Stratégie de correspondance :
Correspondance Floue(pour éviter de manquer des correspondances en cas de fautes de frappe sur le nom).
Colonnes récupérées :
ProfileID,StatutCompteNombre de correspondances : 1 (seule la meilleure correspondance est récupérée)
Après Transformation :
CustomerID |
Nom |
ProfileID |
StatutCompte |
|
|---|---|---|---|---|
1 |
John Doe |
101 |
Actif |
|
2 |
Jane Smith |
204 |
Inactif |
Dans cet exemple, la transformation enrichit le jeu de données d’origine en ajoutant les colonnes ProfileID et StatutCompte depuis le Référentiel des Comptes, sur la base de la meilleure correspondance trouvée pour chaque nom de client.