5. Planifier et lancer les flows, poser des alertes
5.1. Planification et exécution des flows
Les flows permettent de concevoir à la souris des traitements à déployer en production, il est donc particulièrement aisé d’exécuter des flows.
Tale of Data permet d’exécuter des traitements modélisés en graphes orientés sans cycles, connexes (i.e. l’ensemble des processeurs doivent être, même indirectement, connectés).
Dès lors qu’un flow est valide, le bouton d’exécution du flow  est activé dans la Barre d’outils :
est activé dans la Barre d’outils :
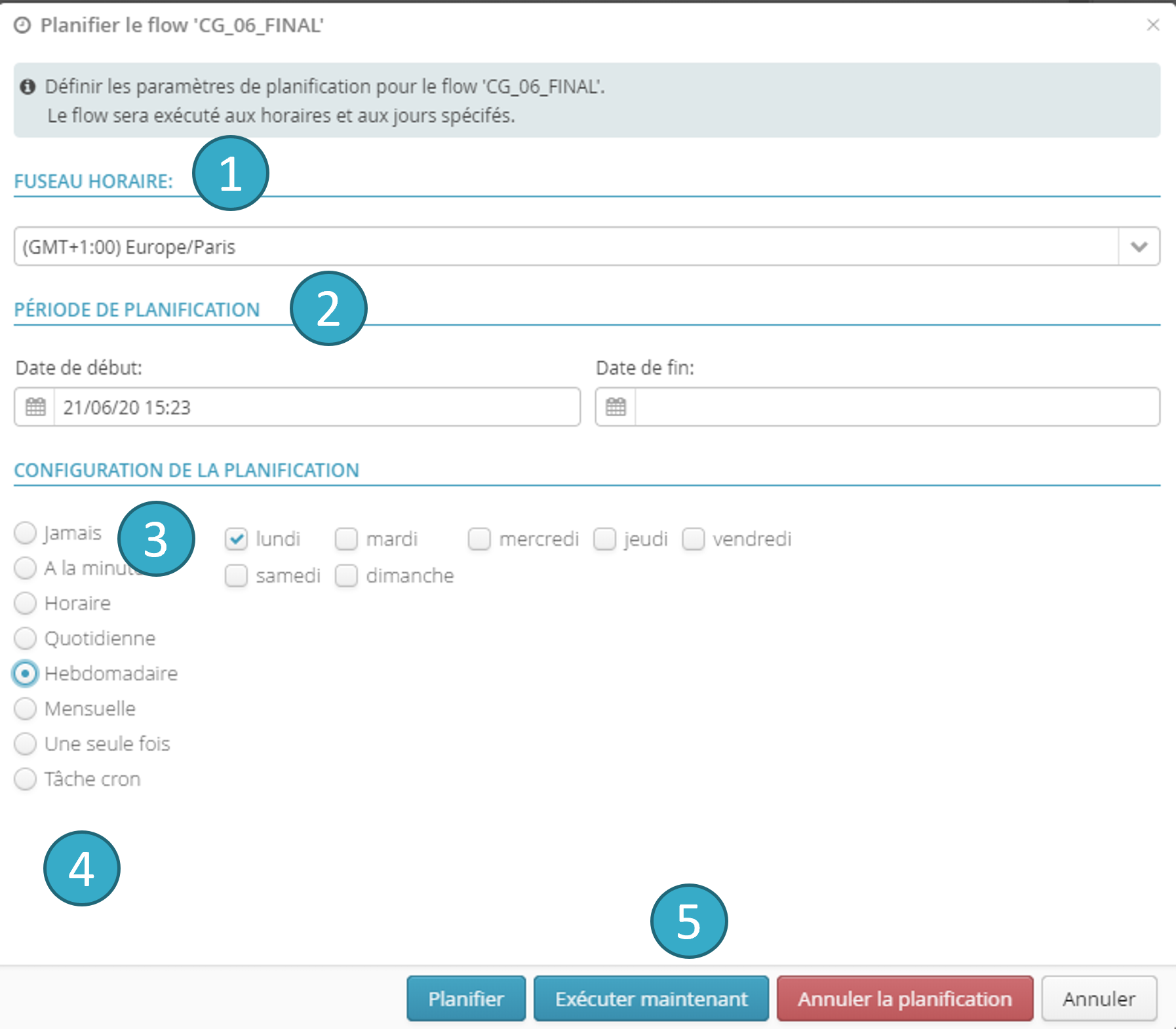
Un clic sur ce bouton ouvre une fenêtre de dialogue permettant de planifier l’exécution du flow. Il est possible :
De préciser un fuseau horaire
.
De préciser une plage de planification (date / heure de début et de fin)
: aucune exécution ne sera lancée à l’extérieur de cette plage.
De configurer des exécutions répétées à une échelle de temps allant de la minute au mois
.
De spécifier (réservé aux experts) une expression Cron
[2].
Ou tout simplement d’exécuter le flow immédiatement, une seule fois
.
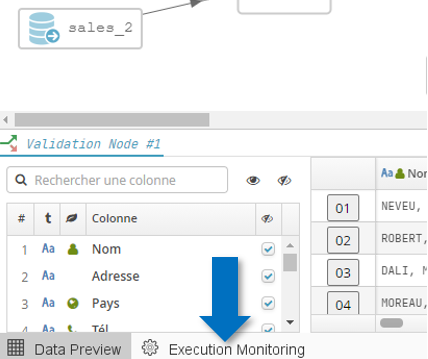
L’exécution des flows est orchestrée par un serveur différent de celui de l’application web principale. Cependant, les différents évènements liés à l’exécution des Flows (démarrage, progression, succès, échec) sont accessibles depuis l’interface web. Pour accéder à cette information, il suffit de cliquer sur le bouton Execution Monitoring en bas à gauche de l’écran (à côté du bouton Data Preview) :
Une vue affiche alors la liste des dernières exécutions du flow (par défaut les flows exécutés au cours des 10 derniers jours). Les informations suivantes sont accessibles :
Le statut de l’exécution (Succès, Échec, En cours).
Les détails : un bouton permet de retrouver dans le Catalogue, si l’exécution a réussi, l’ensemble des cibles alimentées par l’exécution du flow. En cas d’échec, des messages d’erreurs sont accessibles.
Les tâches réussies rapportées au total.
Les sous-tâches réussies rapportées au total. Il faut noter qu’une exécution étant un processus distribué, elle ne consomme pas forcément toutes les sous-tâches allouées par le plan d’exécution : l’exécution peut donc se terminer avec succès même s’il reste des sous-tâches.
Les données lues en octets ET en nombre d’enregistrements.
Les données écrites en octets ET en nombre d’enregistrements.
Les heures de début et de fin effectives (si l’exécution n’est pas encore terminée, la date de fin est vide).
La durée totale d’exécution du flow.
L’heure de début telle qu’initialement planifiée.
La prochaine heure d’exécution, si la planification est répétitive et qu’il reste au moins une exécution.
Si le flow est en cours d’exécution, lorsqu’un événement de progression est reçu, les cellules concernées apparaissent pendant quelques secondes en jaune :

En cas de succès, un clic sur le bouton Afficher les résultats (cf. fig. ci-dessus) permet d’ouvrir une fenêtre de dialogue proposant un lien vers chaque jeu de données créé ou modifié par le flow :
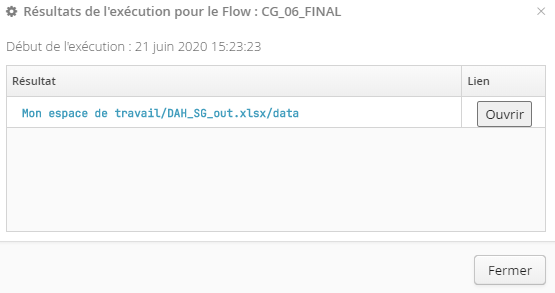
Un clic sur le bouton Ouvrir (cf. fig. ci-dessus) à droite de chaque jeu de données produit par un sink permet d’accéder à une prévisualisation des données via le Catalogue.
5.2. Mise en place d’une alerte dans un flow
Les alertes se posent sur les cibles (alias cible). Elles permettent d’être informé lorsque les enregistrements écrits dans une cible valident un critère d’activation. Par exemple : recevoir une alerte lorsqu’une cible, collectant les enregistrements invalides, a écrit des enregistrements.
Pour poser une alerte, dans la zone de configuration en bas à droite, cliquer sur le bouton Alerte  ayant une cloche comme icône :
ayant une cloche comme icône :
On peut préciser le nombre minimum ou maximum d’enregistrements qui doivent être écrits dans la cible, à l’exécution du flow :
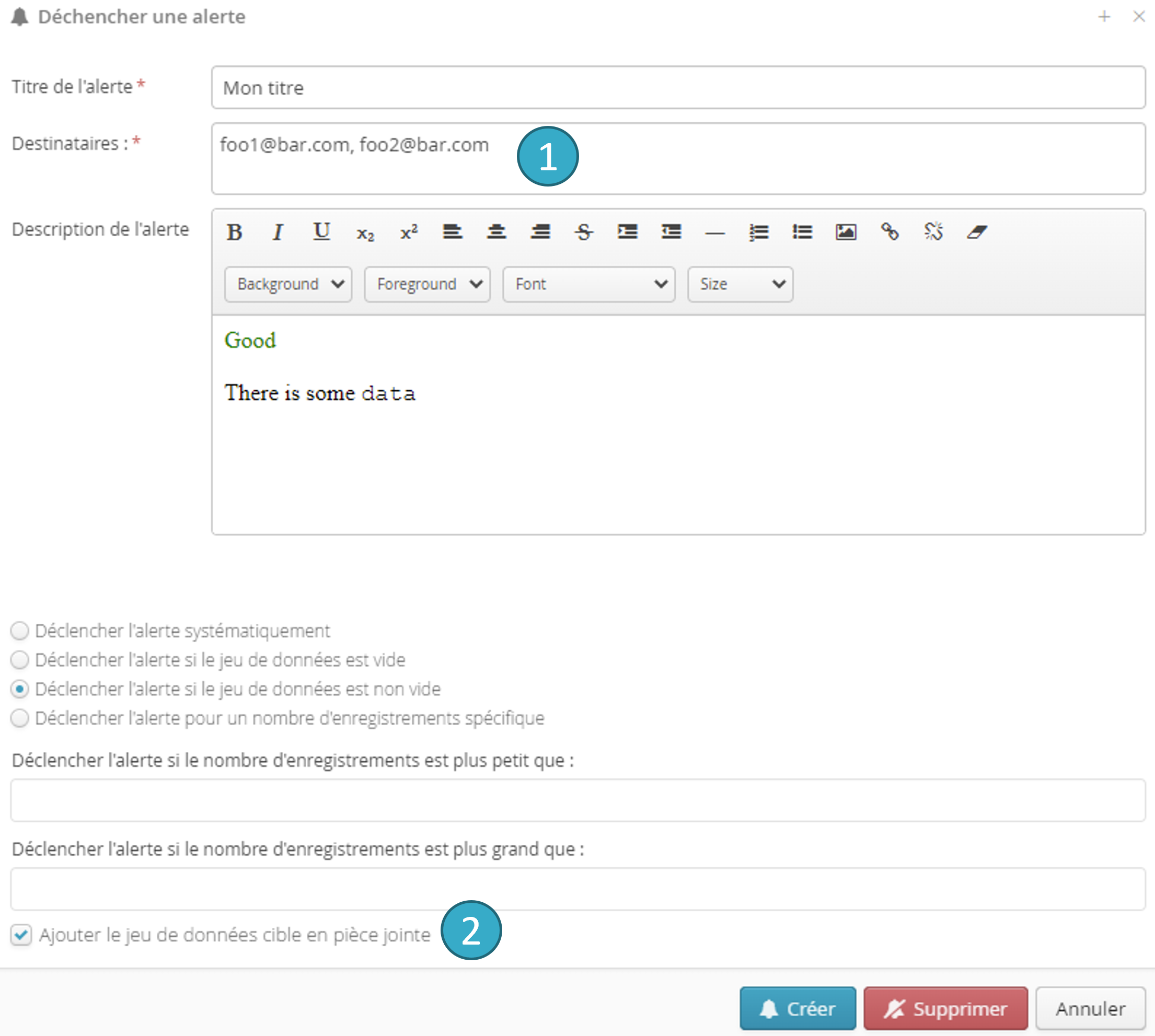
Quand une alerte est positionnée, l’icône du bouton Alerte devient rouge :
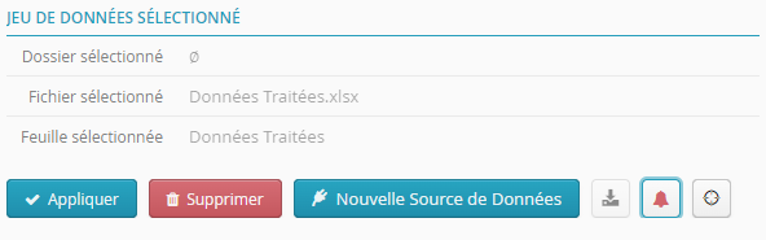
Ne pas oublier de cliquer sur le bouton Appliquer pour enregistrer les changements sur la cible et donc activer l’alerte.
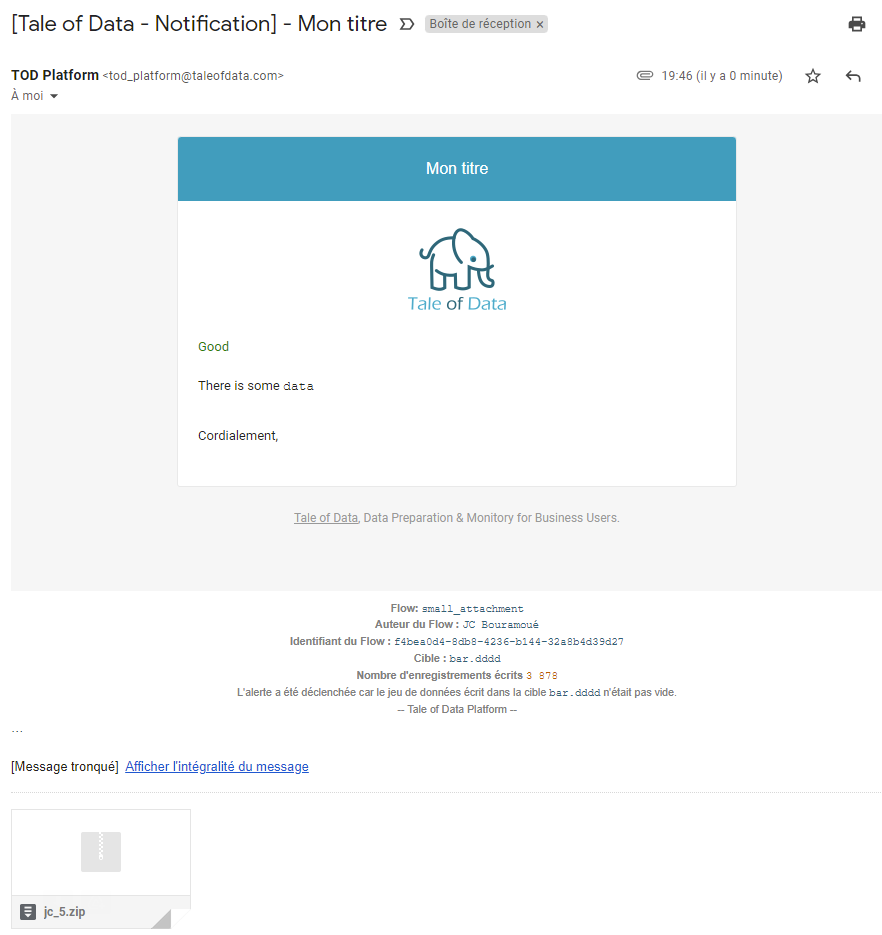
Si à l’exécution, les conditions de déclenchement de l’alerte sont réunies, un e-mail est envoyé aux personnes mentionnées dans le champ Destinataires : il est possible d’indiquer plusieurs destinataires en séparant les différents e-mails par des virgules.
Il est également possible de joindre le jeu de données cible au mail d’alerte en cochant l’option Ajouter le jeu de données en pièce jointe  .
.
Prudence
La taille de la pièce jointe est limitée à 2 mégaoctets par défaut (ce paramètre peut être augmenté, nous consulter).
Si la cible est un fichier Excel et que celui-ci ne dépasse pas la taille limite, le fichier Excel est envoyé en pièce jointe. Cette fonctionnalité peut-être très utile lorsqu’on la combine avec l’écriture, depuis un flow, dans un onglet d’un fichier Excel existant. Tale of Data permet ainsi de mettre à jour des graphiques Excel en écrivant dans le ou les onglets contenant les données alimentant les graphiques en question.
Si la cible n’est pas un fichier Excel (ou bien est un Excel trop volumineux), un fichier CSV zippé est envoyé en pièce jointe : le nombre de lignes du CSV peut être limité par Tale of Data afin de ne pas dépasser la taille maximum pour la pièce jointe.
Exemple de mail d’alerte avec pièce jointe :
5.3. Planification et exécution des séquences de Flows
Note
Si vous vouliez en savoir plus sur cette fonctionnalité, un tutoriel elearning est disponible ci-dessous :
Utiliser les séquences de flows
Dans cette vidéo nous vous montrons comment créer et lancer une séquence de flows. Ceci veut dire que vous pouvez dire à Tale of Data de lancer certains flows les uns après les autres automatiquement, sans avoir besoin de le faire vous-même à la main. Vous pouvez aussi planifier l’exécution de la séquence comme usuellement pour les flows.
La fonctionnalité Séquence de Flows permet d’exécuter une suite de flows dans un ordre défini par l’utilisateur, en ayant l’assurance que chaque flow de la séquence ne démarre qu’une fois l’exécution de son prédécesseur terminée.
L’accès à la vue permettant de gérer des séquences de flows s’effectue via le menu Exécutions des flows en cliquant sur l’icône de « liste » .
La vue séquence permet de créer / modifier / exécuter / supprimer des séquences de flows.
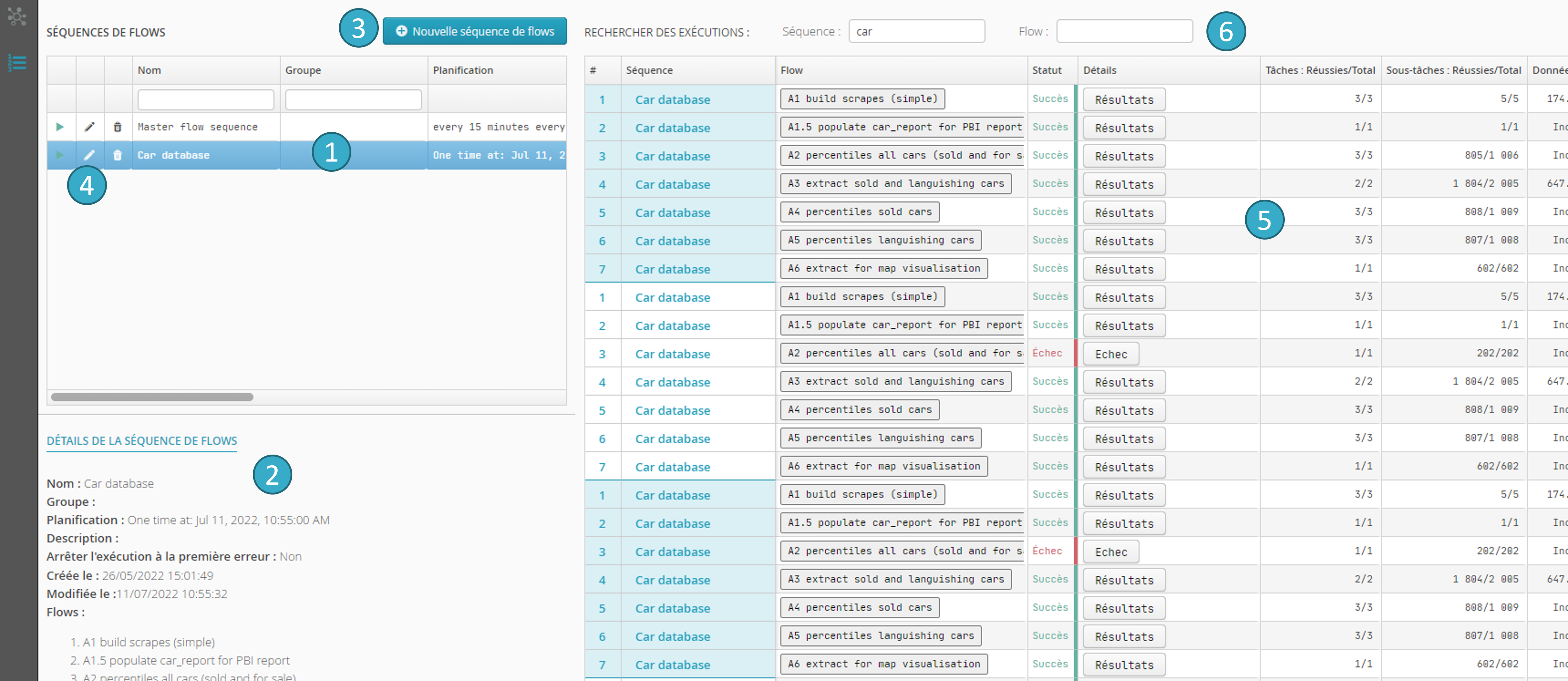
Liste des séquences existantes
.Détails de la séquence
sélectionnée dans la liste précédente, avec notamment :La liste des flows constituant la séquence.
L’option Arrêter l’exécution à la première erreur.
Le bouton permettant de créer une nouvelle séquence
 .
.Le bouton permettant de modifier une séquence existante
 .
.La zone d’exécution des séquences
 qui contient des informations semblables à celles proposées dans la vue exécution des flows (voir Planification et exécution des flows) avec deux colonnes en plus sur la gauche montrant la séquence à laquelle est rattaché le flow en train de s’exécuter.
qui contient des informations semblables à celles proposées dans la vue exécution des flows (voir Planification et exécution des flows) avec deux colonnes en plus sur la gauche montrant la séquence à laquelle est rattaché le flow en train de s’exécuter.La zone de filtrage
 permettant de visualiser un sous-ensemble des séquences ou des flows.
permettant de visualiser un sous-ensemble des séquences ou des flows.
Pour ajouter une nouvelle séquence, cliquer sur le bouton :

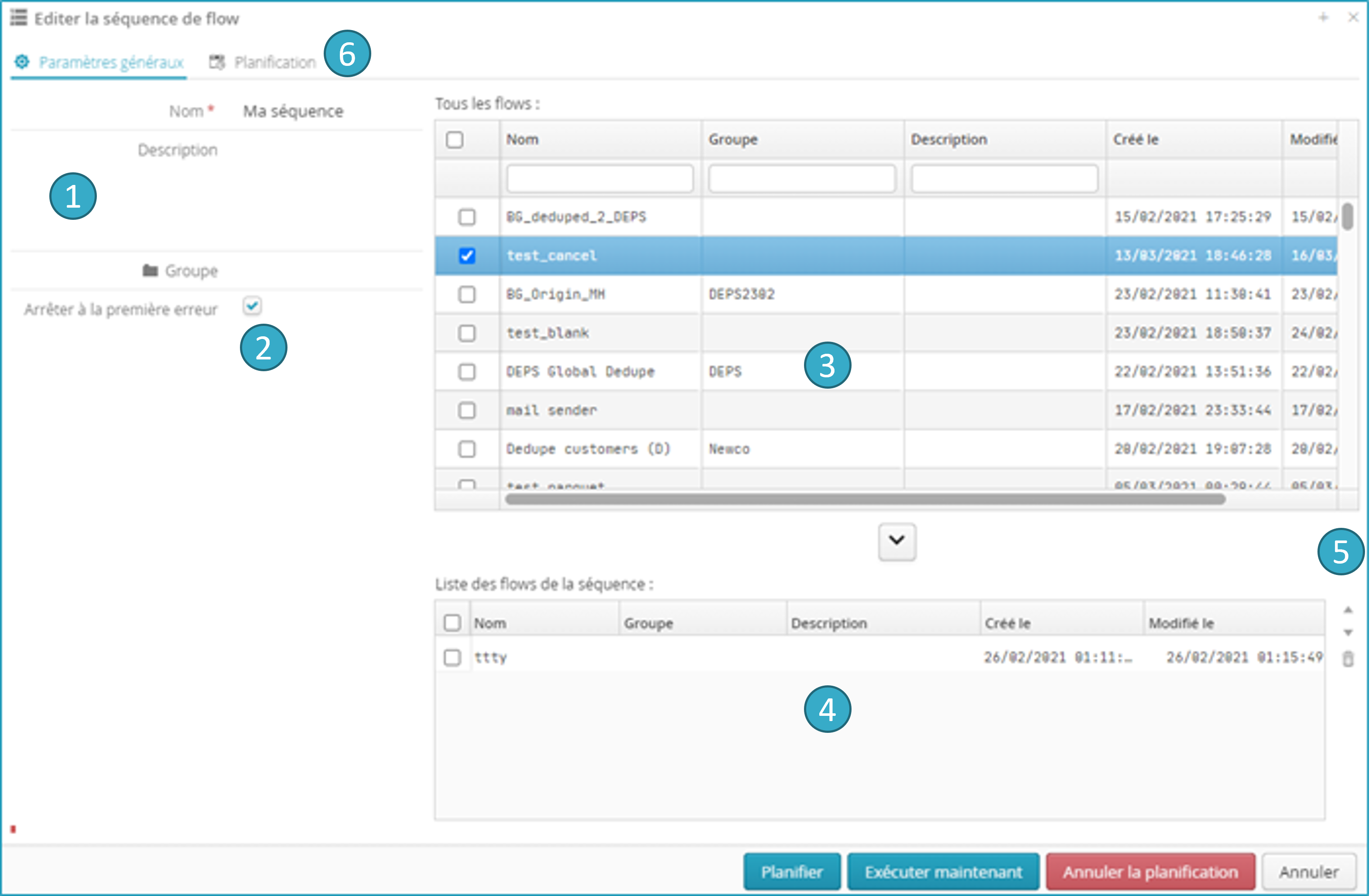
Informations générales sur la séquence
.Arrêter l’exécution à la première erreur
. Si cette option est sélectionnée, la séquence est arrêtée dès la première erreur. Les exécutions de flow postérieures à l’échec sont abandonnées.Zone listant les flows de l’utilisateur
.Zone listant les flows de la séquence
. Le bouton entre les 2 zones permet d’ajouter un flow dans la séquence.Zone de boutons
permettant de réordonner les flows de la séquence et également de supprimer des flows de la séquence.La zone de planification de la séquence
(voir Planification et exécution des flows).
5.4. Exécution en mode batch
Un flow peut être exécuté en mode batch.
L’exécution d’un flow en mode batch consiste à désigner un nœud source appelé source paramètre (impérativement de type fichier) et à répéter plusieurs fois, séquentiellement, l’exécution de ce flow en changeant à chaque fois le jeu de données vers lequel pointe le nœud source paramètre.
Prudence
Un flow contient au plus un nœud source paramètre.
Il est ainsi possible d’appliquer successivement le même flow à plusieurs jeux de données et de collecter les résultats de l’ensemble des exécutions.
Les jeux de données impliqués dans le batch doivent impérativement être de type fichier et avoir la même structure que le nœud source paramètre. Tous les types de fichiers (CSV, Excel, XML, JSON) sont acceptés.
5.4.1. Configuration du mode batch
Pour configurer le mode batch sur un flow, ouvrez le flow dans l’éditeur et cliquez sur le bouton vertical Batch à droite de l’écran :
Note
Le mode batch se configure pour l’intégralité d’un flow : il n’est pas lié à un nœud source particulier
Vous accédez alors à l’écran de configuration du batch. La configuration du batch nécessite de spécifier les propriétés suivantes :
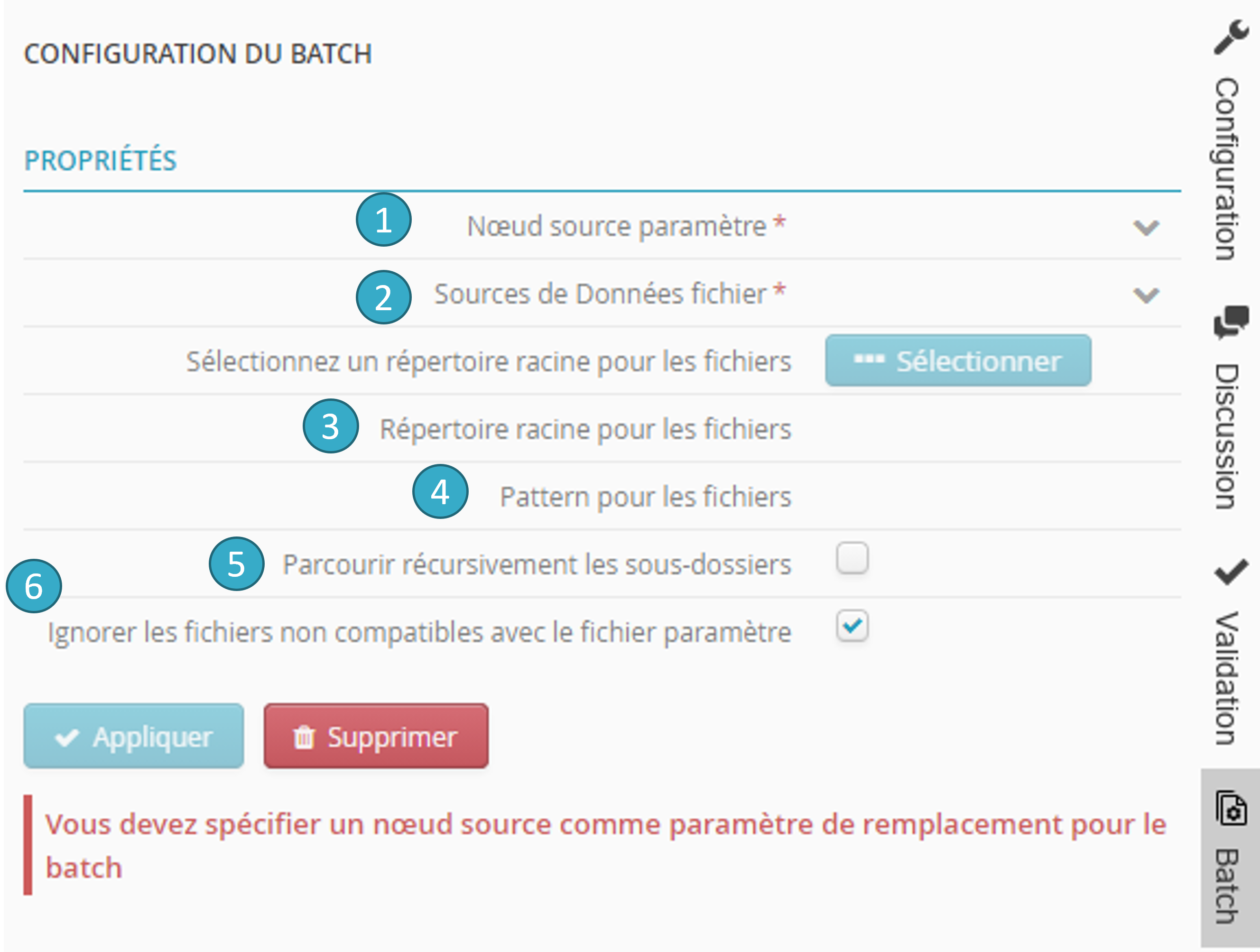
Nœud source paramètre
: il s’agit du nœud source « place holder » qui, à chaque itération, lira les données de chacun des fichiers du batch.Source de Données fichier
: c’est la source de données dans laquelle seront recherchés les fichiers à inclure dans le batch. Il ne peut s’agir que d’une source de données de type fichier (e.g. Mon espace de travail, Azure Blob Storage, Amazon s3, site SFTP, etc.).Répertoire racine pour les fichiers
: il s’agit du répertoire racine à partir duquel seront recherchés les fichiers à inclure dans le batch. Si aucun répertoire n’est précisé, les fichiers du batch seront recherchés à partir de la racine de la source de données fichier définie à l’étape précédente.Pattern pour les fichiers
: Pattern (les caractères spéciaux * et ? sont autorisés) pour les noms des fichiers à inclure dans le batch. Si ce champ est laissé vide, tous les fichiers rencontrés seront inclus dans le batch.Parcourir récursivement les sous-dossiers
: si l’option est cochée, les sous-répertoires du Répertoire racine pour les fichiers seront, à leur tour, parcourus à la recherche de fichiers à inclure dans le batch (et ainsi de suite récursivement).Ignorer les fichiers non compatibles avec le fichier paramètre
: les fichiers à inclure dans le batch doivent impérativement être du même type que celui du nœud source paramètre (e.g. si le fichier du nœud source paramètre est de type CSV, alors tous les fichiers du batch doivent être de type CSV). La structure (nombre de champs) ainsi que les propriétés (ex : format de dates, en-têtes sur la 1re ligne ou encore séparateur pour un fichier CSV) doivent également être les mêmes. Si cette option est cochée, les fichiers incompatibles seront silencieusement écartés du batch (par exemple les fichiers vides). En revanche, si l’option n’est pas cochée, une erreur sera déclenchée et le batch échouera.
Lorsque la configuration du batch est terminée, cliquer sur le bouton Appliquer pour la rendre effective :
Appliquer
: permet de rendre la configuration du batch effective.Supprimer
: supprime le batch.Batch
: l’icône du bouton apparaît en bleu lorsqu’un mode batch est actif.
5.4.2. Exécution d’un flow en mode batch
Un flow en mode batch s’exécute exactement comme les autres flows : il suffit de planifier l’exécution ou de lancer une exécution immédiate en utilisant le bouton Exécuter dans la Barre d’outils.
5.4.3. Traçabilité de l’exécution d’un batch
Lorsqu’un flow est exécuté en mode batch, des informations de progression sont disponibles dans la vue Execution Monitoring :

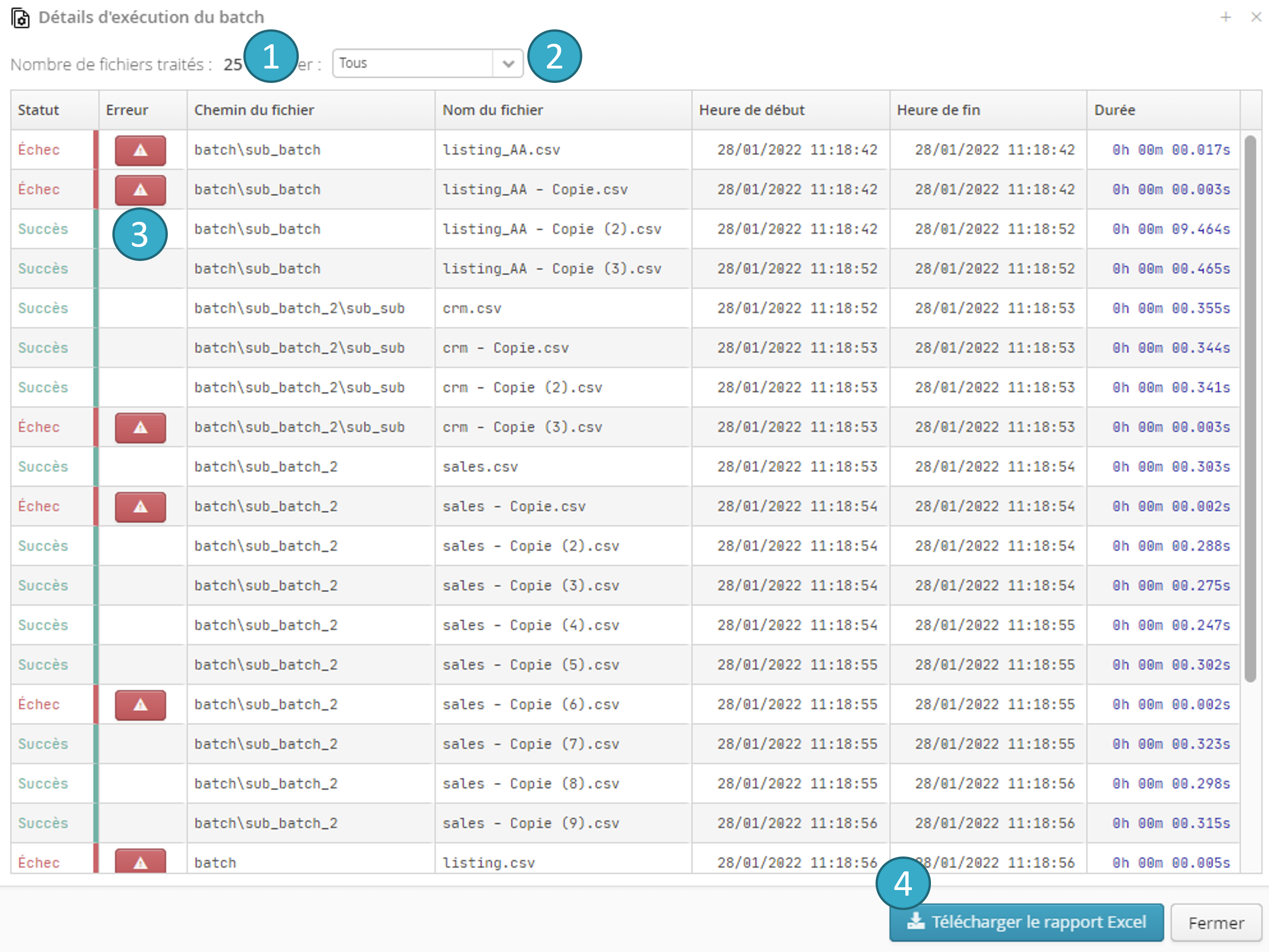
Cliquer sur le bouton permet d’ouvrir la fenêtre Détails d’exécution du batch :
Cette fenêtre est accessible dès le démarrage du batch dont elle affiche l’état courant. Chaque ligne représente un fichier traité par le batch (ou en cours de traitement).
Il est possible :
D’accéder au nombre de fichiers traités au moment de l’ouverture de la fenêtre
De filtrer par statut d’exécution (En cours, Succès, Échec)
D’accéder à des informations sur l’échec du traitement d’un fichier particulier en cliquant sur le bouton
De télécharger les données affichées dans cette vue au format MS Excel en cliquant sur le bouton
Prudence
Le processus de batch se poursuit même en cas d’échec sur un ou plusieurs fichiers. La fenêtre Détails d’exécution du batch permet à tout moment de visualiser les fichiers en échec.
5.4.4. Important : Bonnes pratiques pour l’exécution de flows en mode batch
Le mode batch peut impliquer un nombre de fichiers pouvant aller de quelques-uns à plusieurs dizaines de milliers.
Il convient donc de prendre un certain nombre de précautions afin d’éviter des temps d’exécution très longs consommant une grande partie des ressources CPU et mémoire de la plateforme, au détriment d’autres traitements.
Astuce
Toujours tester le flow d’abord sans le mode batch (donc uniquement avec les données du nœud source paramètre). Cela permet de se rendre compte d’éventuels problèmes de performances et d’optimiser un flow avant de lancer un batch.
Astuce
Eviter de répéter les mêmes calculs au fil des itérations du batch.
Considérons par exemple ce flow :
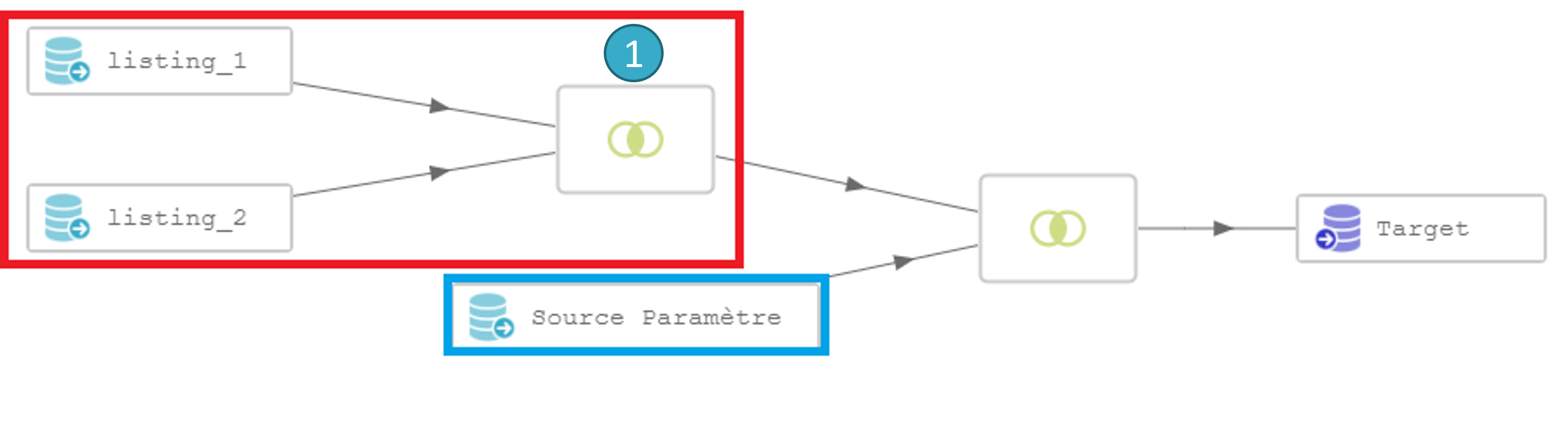
En analysant le flow ci-dessus, on constate que la jointure entre listing_1 et listing_2 (encadrée en rouge) est totalement indépendante des itérations du batch (le nœud source paramètre est encadré en bleu). A l’exécution du batch, la jointure , potentiellement coûteuse sera exécutée à l’identique à chaque itération, ce qui peut être très pénalisant lorsque l’on a des milliers ou des dizaines de milliers de fichiers à traiter.
La solution est de précalculer la jointure entre listing_1 et listing_2 dans un flow séparé puis d’utiliser le résultat dans le flow à exécuter en batch comme ceci :
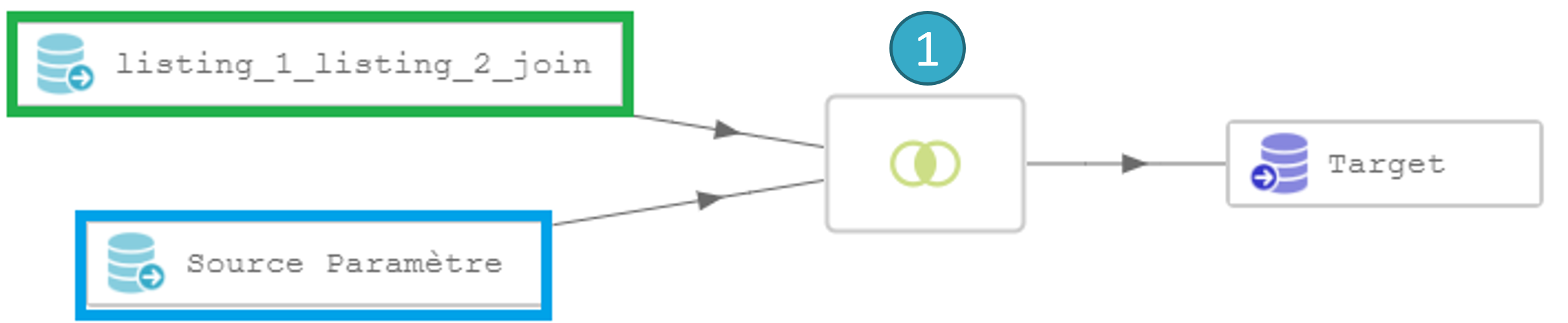
Supposons que le calcul de la jointure prenne 10 secondes, le fait de l’exécuter en batch par exemple, 10 000 fois (si on a 10 000 fichiers dans le batch), demandera 100 000 secondes soit presque 28 heures.
Précalculer cette jointure dans un flow séparé permet donc d’économiser 28 heures de traitement inutile.
Prudence
Au-delà de quelques dizaines de fichiers dans un batch nous conseillons fortement de n’utiliser dans votre flow que des cibles de type base de données relationnelles.
En effet, du fait de sa capacité à distribuer les calculs, le moteur de Tale of Data crée des fichiers fragmentés (par exemple un CSV dans Tale of Data peut être un répertoire composé d’un grand nombre de petits fichiers CSV).
Sur un batch impliquant, par exemple, 10 000 fichiers, la cible peut donc être un CSV fragmenté en 10 000 sous-fichiers, voire plus. Si le résultat du batch est exploité dans Tale of Data, cela ne pose qu’un problème de performance (= lenteur pour reconstituer les données réparties sur plusieurs milliers de fragments de fichiers). En revanche, si l’objectif est d’exploiter les résultats du batch avec une application tierce (e.g. suite de reporting, solution de Data Visualisation,…) alors utiliser une base de données comme cible est la seule solution réellement viable pour des batch de taille conséquente.
5.5. Lancement de flows et de séquences de flows par API
Tale of Data peut être intégré dans des systèmes complexes à travers une API de déclenchement d’exécutions. Celle-ci permet de lancer des flows et des séquences de flows, et également de récupérer des informations sur la progression et la bonne réalisation de ces exécutions. Ainsi, un script, un autre logiciel, un système d’orchestration, par exemple, pourront intégrer une série de traitements Tale of Data à certains moments de leur propre parcours d’exécution.
5.5.2. API de lancement de flows
- Lancement d’un flow
Le lancement se fait en appelant l’URL:
https://www.mytaleofdataserver.com/api/v2/flow-engine/run-flow/ flow_uuid / api_key
L”uuid du flow
flow_uuidest disponible dans l’éditeur de flow, une fois ouvert le flow concerné:
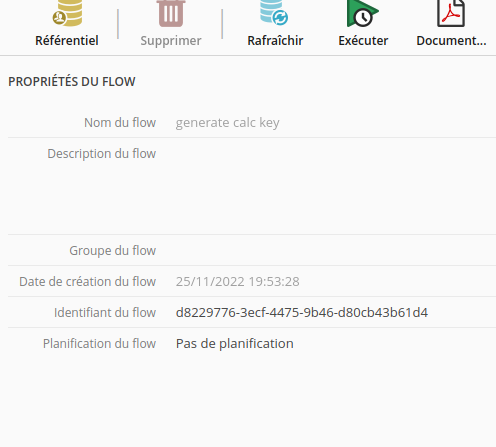
api_keyest la clé d’API individuelle de l’utilisateur propriétaire du flow concerné (voir Comment obtenir votre clé d’API).
Cet appel de lancement retourne un objet JSON contenant des informations sur le succès du lancement et qui permettent d’interroger le serveur sur l’état de progression du flow :
1{
2 "payload": {
3 "uuid": "89c3573f-dda4-4847-9eac-eb2ea238d5f4"
4},
5 "status" : "OK",
6 "error_message":""
7}
L’entrée payload.uuid est à utiliser pour l’appel suivant, qui sert à contrôler la progression et le bon état de l’exécution qui a été lancée :
- Appel de contrôle de l’état d’exécution :
Le contrôle d’avancement se fait en appelant:
https://www.mytaleofdataserver.com/api/v2/flow-engine/flow-exec-status/ flow_run_uuid / api_keyflow_run_uuidcorrespond aupayload.uuidretourné par l’API de lancement.
La réponse de l’appel ressemble à ceci :
1{
2 "payload" : "RUNNING",
3 "status" : "OK",
4 "error_message": ""
5}
Note
- Les états possibles pouvant être renvoyé par cet appel (champ
payload) sont: SUCCESSRUNNINGFAILURECANCELLEDUNKNOWN
5.5.3. API de lancement de séquences de flows
De manière analogue au lancement de flow, il est possible de lancer une séquence de flows par API.
- Appel de lancement :
Pour lancer une séquence il suffit d’appeler:
https://www.mytaleofdataserver.com/api/v2/flow-engine/run-sequence/ sequence_uuid / api_keyL”uuid de la séquence de flows
sequence_uuidest disponible dans la vue des séquences de flow, une fois ouvert le flow concerné:
api_keyest la clé d’API individuelle de l’utilisateur propriétaire de la séquence de flows concernée (voir Comment obtenir votre clé d’API).
Cet appel de lancement retourne un objet JSON contenant des informations sur le succès du lancement et qui permettent d’interroger le serveur sur l’état de progression de la séquence de flows :
1{
2 "sequence_run_uuid": "d16239d3-b3f5-4f69-b99c-fa955735c4cb",
3 "error_message" : null
4}
Le champ error_message sera null sauf s’il y a eu une erreur.
- Appel de contrôle de l’état d’exécution :
Le contrôle se fera avec:
https://www.mytaleofdataserver.com/api/v2/flow-engine/sequence-exec-status/ sequence_run_uuid / api_keysequence_run_uuidcorrespond ausequence_run_uuidretourné par l’appel de lancement de la séquence.
Dans l’exemple ci-dessous de réponse à cet appel de contrôle d’état, Task 1 est en cours d’exécution, et Task 2 et Task 3 sont en attente :
1{
2 "sequence_run_uuid": "d16239d3-b3f5-4f69-b99c-fa955735c4cb",
3 "items_status_list": [
4 {
5 "task_uuid": "2e53ff48-5fa7-4559-b7dd-7cbacc2652e8",
6 "task_name": "Task 1",
7 "status" : "RUNNING",
8 "error" : null
9 },
10 {
11 "task_uuid": "a06573ce-13fc-47fc-8f6d-dd764e4c2386",
12 "task_name": "Task 2",
13 "status" : "WAITING",
14 "error" : null
15 },
16 {
17 "task_uuid": "47a49198-61b4-4569-833a-c094f1b53477",
18 "task_name": "Task 3",
19 "status" : "WAITING",
20 "error" : null
21 }
22 ],
23 "error_message": null,
24 "success" : false,
25 "finished" : false
26}
Un peu plus tard, Task 1, Task 2 et Task 3 ont toutes fini d’exécuter :
1{
2"sequence_run_uuid": "d16239d3-b3f5-4f69-b99c-fa955735c4cb",
3"items_status_list": [
4 {
5 "task_uuid": "2e53ff48-5fa7-4559-b7dd-7cbacc2652e8",
6 "task_name": "Task 1",
7 "status" : "SUCCESS",
8 "error" : null
9 },
10 {
11 "task_uuid": "a06573ce-13fc-47fc-8f6d-dd764e4c2386",
12 "task_name": "Task 2",
13 "status" : "SUCCESS",
14 "error" : null
15 },
16 {
17 "task_uuid": "47a49198-61b4-4569-833a-c094f1b53477",
18 "task_name": "Task 3",
19 "status" : "SUCCESS",
20 "error" : null
21 }
22],
23"error_message": null,
24"success" : true,
25"finished" : true
26}
Note
- Les états possibles des champs
items_status_list[n].payloadsont: WAITINGRUNNINGSUCCESSFAILURECANCELLED
Note
Suivant les réglages de la séquence, il est possible que certains des flows de la séquence puissent avoir échoué sans que la séquence ait fini d’exécuter. Pour plus de détails, consulter la section sur le paramétrage des séquences de flows.
5.5.1. Comment obtenir votre clé d’API
Chaque utilisateur de Tale of Data possédant une licence Entreprise peut effectuer ces lancements par API sur les flows de son environnement. Une clé d’API individuelle est nécessaire, celle-ci est fournie sur simple demande par le support Tale of Data.
Note
Dans toute la suite, les points d’entrée des API seront notées sous la forme:
https://www.mytaleofdataserver.com:/api/v2/flow-engine/<endpoint>www.mytaleofdataserver.comest à remplacer par l’URL de votre serveur Tale of Data.