6.19. Transformations avancées
6.19.1. Découper un tableau
Avec cette transformation, l’enregistrement présent dans le tableau d’entrée, sera découpé en trois enregistrements :
tableau d’entrée :
A
B1,B2,B3
C
tableau de sortie :
A
B1
C
A
B2
C
A
B3
C
La transformation s’applique sur un unique champ.
La transformation utilise le ou les filtres actifs.
Note
Exemple pratique : Découper un tableau
Avant Transformation
ID |
Produits |
|---|---|
1 |
Apple, Banana, Grape |
2 |
Orange; Mango |
3 |
PeachnPineapple |
Dans cet exemple, la colonne Produits contient plusieurs articles séparés par des virgules, des points-virgules et des retours à la ligne.
Configuration de Transformation
Colonne Cible :
ProduitsCaractères Séparateurs :
,;Caractères à Supprimer :
""(aucun)Utiliser les retours à la ligne comme séparateur :
trueFiltres : Aucun (appliquer à toutes les lignes)
Après Transformation
ID |
Produits |
|---|---|
1 |
Apple |
1 |
Banana |
1 |
Grape |
2 |
Orange |
2 |
Mango |
3 |
Peach |
3 |
Pineapple |
Le jeu de données transformé contient désormais chaque produit en tant qu’entrée distincte, ce qui facilite l’analyse individuelle des articles sans gérer de listes concaténées.
6.19.2. Ensemble de Règles Métier
Note
Si vous vouliez en savoir plus sur cette fonctionnalité, un tutoriel elearning est disponible ci-dessous :
Utiliser les règles métier
Si vous ne connaissez pas encore les règles métier, c’est le moment de les découvrir! Elles sont d’une souplesse et d’une puissance inégalées pour tous les besoins que vous avez de modifier vos données suivant certaines règles. Vous pouvez y accéder dans l’éditeur de préparation, et créer autant de règles que vous le souhaitez.
Un ensemble de règles métier permet, sans écrire de code :
D’effectuer des calculs sur l’enregistrement courant.
De rajouter de nouveaux champs dont la valeur sera calculée à partir des champs existants dans l’enregistrement courant.
Les règles métier de calcul ont la structure suivante :
IF : <Ajouter les conditions séparées par AND/OR>.
Then : <Ajouter les calculs à effectuer si la condition IF est satisfaite>.
Else : <Ajouter les calculs à effectuer si la condition IF n’est pas satisfaite>.
Cliquez sur le bouton Ajouter pour créer une nouvelle règle de calcul :
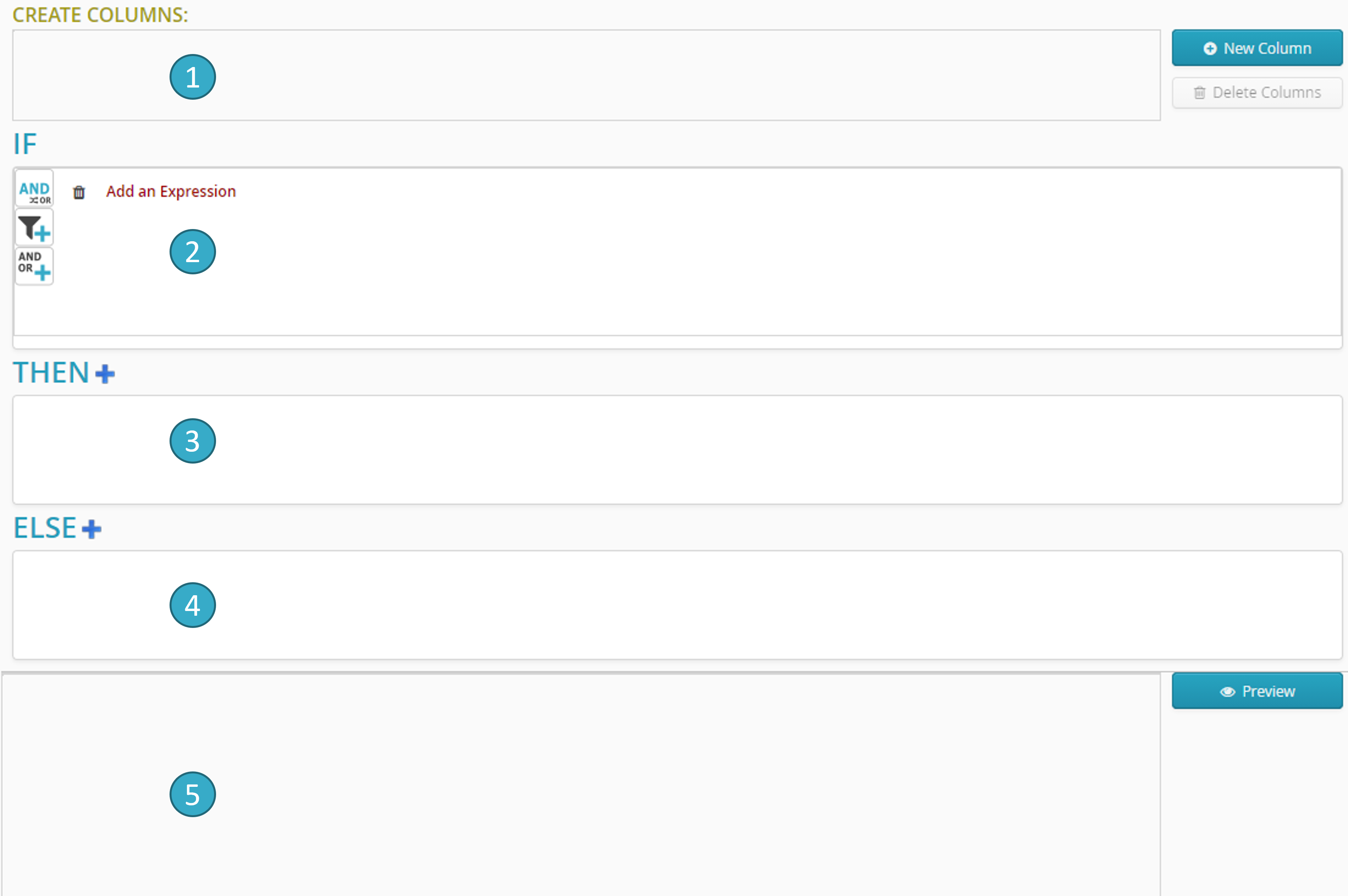
L” *éditeur de règles métier* présente les zones suivantes :
Zone de création de nouveaux champs calculés
.
Zone de définition de la condition IF
.
Zone de définition des calculs à effectuer dans la clause THEN
.
Zone de définition des calculs à effectuer dans la clause ELSE
.
Zone de prévisualisation des résultats du calcul
.
Pour ajouter une condition, cliquez sur le label « Add an Expression » dans la zone . Une fenêtre de dialogue s’ouvre :
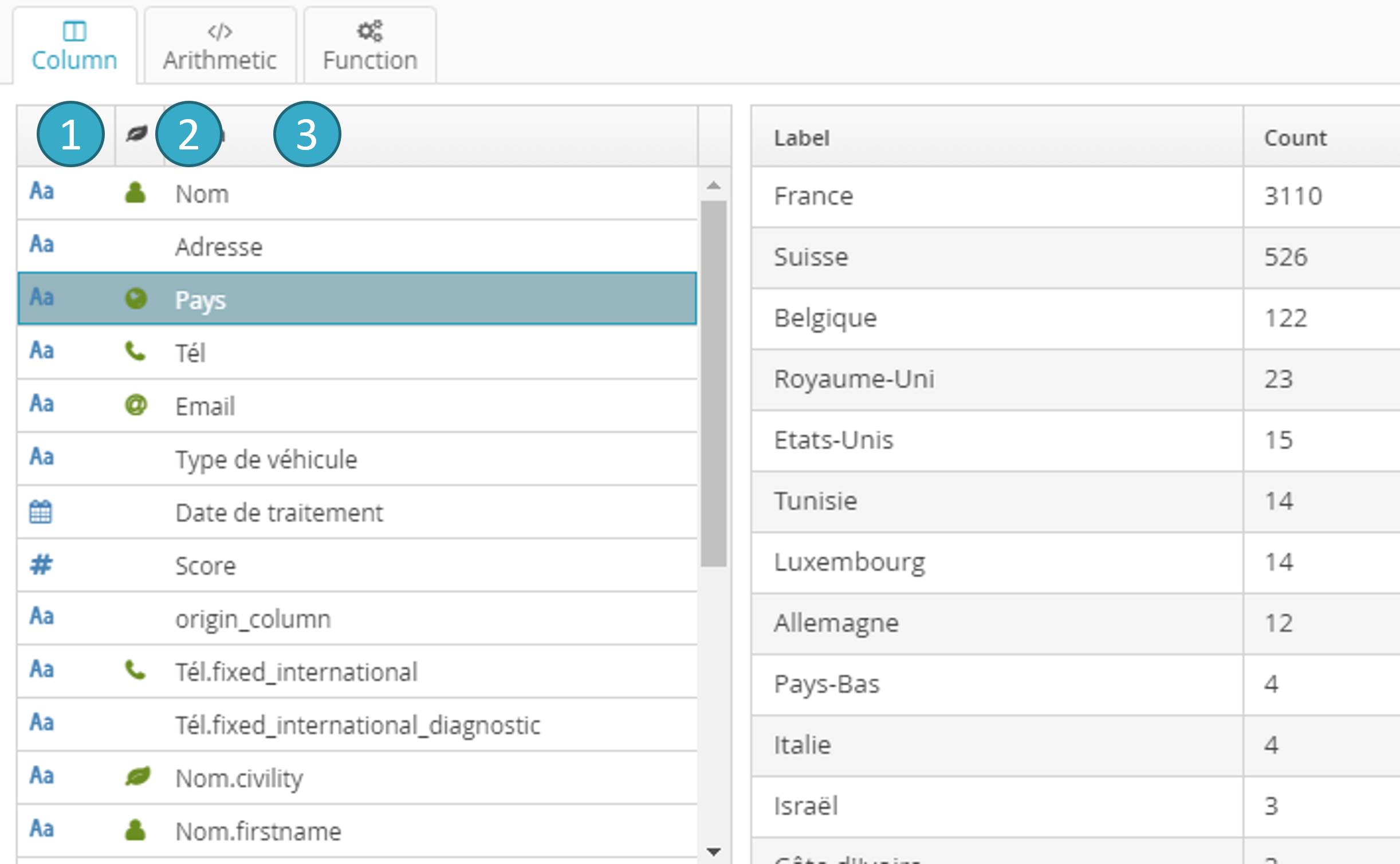
En partie gauche d’une condition, vous pouvez ajouter au choix :
Un champ
Une expression arithmétique
Une fonction
Comme indiqué sur la capture d’écran ci-dessous, vous devez ensuite ajouter la partie droite de la condition en cliquant sur le label « Add an Expression » à droite de l’opérateur :
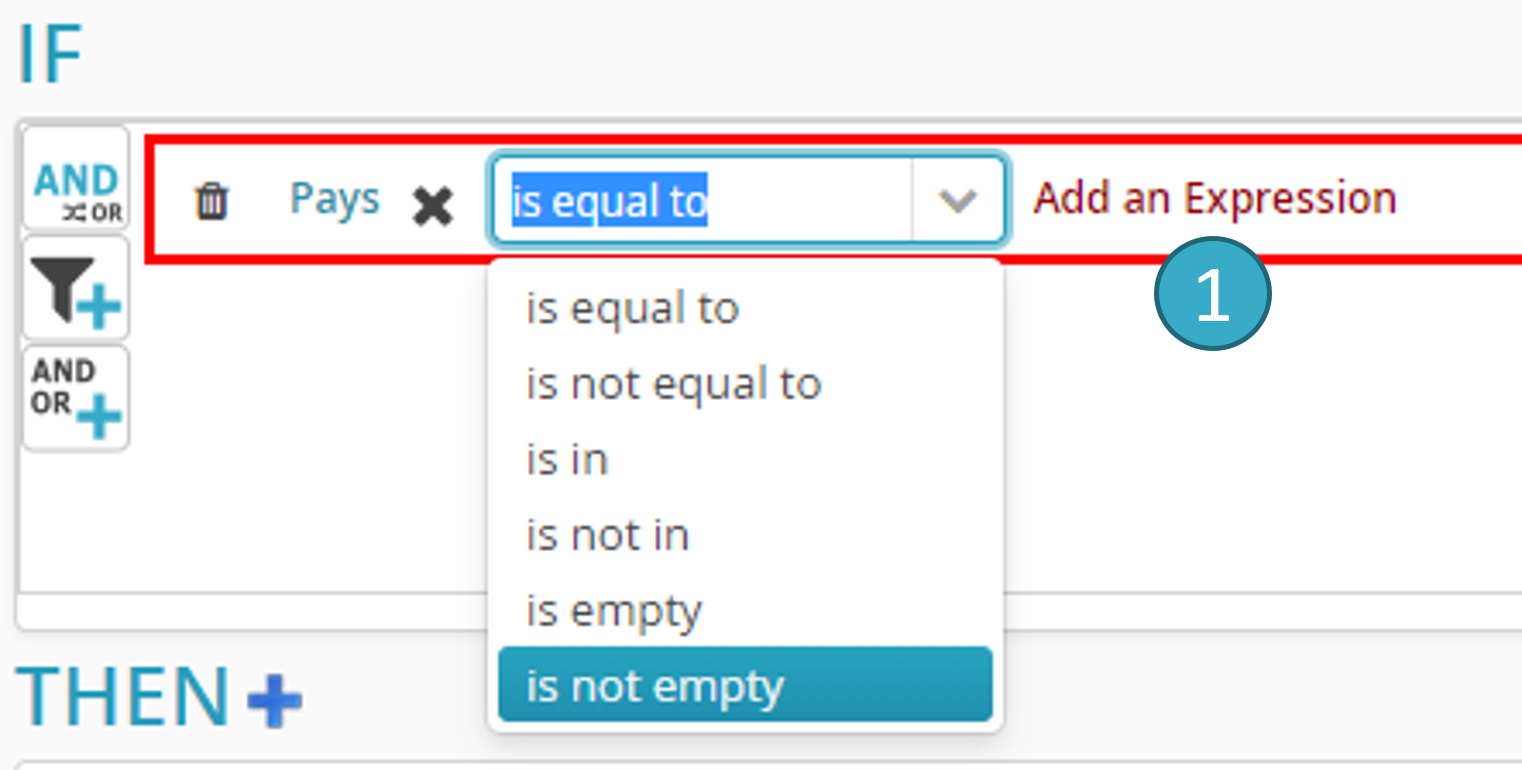
En partie droite d’une condition, vous pouvez spécifier au choix :
Un littéral (un nombre, un texte, une date, …).
La valeur d’un autre champ (e.g. IF champ1 = champ2).
Le résultat d’une fonction.
Pour ajouter un calcul dans la clause THEN ou ELSE, cliquez sur le + dans la zone ou . Une fenêtre de dialogue similaire à la fenêtre d’édition des conditions vous permet alors d’assigner à des champs le résultat d’un calcul. Ce calcul peut être :
Un littéral (e.g. champ1 = 12).
La valeur d’un autre champ (e.g. champ1 = champ2).
Le résultat d’une fonction (e.g. champ1 = 3 premiers caractères du champ2).
Une expression arithmétique (e.g. champ1 = champ2 * champ3 + 10).
La suppression d’une règle métier se fait en cliquant sur le bouton de suppression situé à côté de la règle concernée, ou sur le bouton situé en haut pour supprimer l’ensemble des règles métiers présentes dans l’éditeur de préparation :
Note
Exemple pratique : appliquer une règle métier
Avant la transformation :
ID |
Ventes |
Région |
|---|---|---|
1 |
150 |
Est |
2 |
200 |
Ouest |
3 |
120 |
Est |
Configuration de la transformation :
Règle 1 :
Si la région est 'Est', ajouter 10 % aux ventes.Règle 2 :
Si les ventes sont supérieures à 180, étiqueter comme 'Élevé' ; sinon, étiqueter comme 'Normal'.
Après la transformation :
ID |
Ventes |
Région |
Ventes Ajustées |
Étiquette |
|---|---|---|---|---|
1 |
150 |
Est |
165 |
Normal |
2 |
200 |
Ouest |
200 |
Élevé |
3 |
120 |
Est |
132 |
Normal |
Dans cet exemple, la transformation ajuste d’abord les chiffres de vente selon la région. Ensuite, elle applique une étiquette basée sur la valeur ajustée des ventes.
Note
Exemple pratique : mettre à jour une règle de validation métier
Supposons qu’une règle de validation métier soit définie indiquant que SI l’âge est supérieur ou égal à 30 ALORS le statut doit être inactif.
Avant Transformation :
ID |
Nom |
Âge |
Statut |
|---|---|---|---|
1 |
Alice |
34 |
Actif |
2 |
Bob |
17 |
Actif |
3 |
Charlie |
25 |
Actif |
Selon cette règle, la première ligne est invalide.
Configuration de Transformation :
Par exemple, supposons que vous mettiez à jour la règle de validation métier comme suit :
SI l'âge est supérieur ou égal à 22 ALORS le statut doit être inactif
Après Transformation :
ID |
Nom |
Âge |
Statut |
|---|---|---|---|
1 |
Alice |
34 |
Actif |
2 |
Bob |
17 |
Actif |
3 |
Charlie |
25 |
Actif |
Une fois la règle de validation métier mise à jour, seule la deuxième ligne reste valide.
Note
Exemple pratique : supprimer une règle métier
Supposons qu’une règle de validation métier soit définie indiquant que SI l’âge est supérieur ou égal à 30 ALORS le statut doit être Inactive.
Avant Transformation :
ID |
Name |
Age |
Statut |
|---|---|---|---|
1 |
Alice |
34 |
Actif |
2 |
Bob |
17 |
Actif |
3 |
Charlie |
25 |
Inactif |
Selon cette règle, la première ligne ci-dessus est marquée comme invalide.
Configuration de la Transformation :
Aucune configuration, simplement supprimer, dans l’éditeur de préparation, la règle de validation métier :
IF the age is greater than or equal to 30 THEN the status must be inactive
Après Transformation :
ID |
Name |
Age |
Statut |
|---|---|---|---|
1 |
Alice |
34 |
Actif |
2 |
Bob |
17 |
Actif |
3 |
Charlie |
25 |
Inactif |
Une fois la règle de validation métier supprimée, toutes les lignes sont désormais considérées comme valides.
6.19.3. Générer des identifiants uniques
Générer un identifiant unique (UUID) pour chaque enregistrement du jeu de données courant dans un nouveau champ.
La transformation ne s’applique sur aucun champ.
La transformation n’utilise pas le ou les filtres actifs.
Note
Exemple pratique : Générer des identifiants uniques
Avant Transformation :
ID Enregistrement |
Nom |
|
|---|---|---|
1 |
Alice |
|
2 |
Bob |
Configuration de la Transformation :
Nom de la Nouvelle Colonne : « Identifiant Unique »
Après Transformation :
ID Enregistrement |
Nom |
Identifiant Unique |
|
|---|---|---|---|
1 |
Alice |
123e4567-e89b-12d3-a456-426614174000 |
|
2 |
Bob |
987e6543-e21b-12d3-a456-426614174000 |
6.19.4. Inverser les valeurs booléennes
Inverser les valeurs booléennes (vrai, faux) des champs sélectionnés :
La valeur vrai devient faux.
La valeur faux devient vrai.
Les autres valeurs restent inchangées.
La transformation s’applique sur un ou plusieurs champs.
La transformation utilise le ou les filtres actifs.
Note
Exemple pratique : Inverser les valeurs booléennes
Avant Transformation :
Device ID |
GPS Activé |
WiFi Activé |
|---|---|---|
001 |
true |
false |
002 |
false |
true |
Configuration de la Transformation :
Dans cet exemple, nous choisissons d’inverser les valeurs des colonnes “GPS Activé” et “WiFi Activé”.
Colonnes Cibles : GPS Activé, WiFi Activé
Après Transformation :
Device ID |
GPS Activé |
WiFi Activé |
|---|---|---|
001 |
false |
true |
002 |
true |
false |
Cette transformation inverse efficacement les valeurs booléennes pour chaque appareil, basculant ainsi le statut activé/désactivé des fonctionnalités GPS et WiFi.
6.19.5. Réconcilier / Enrichir avec des données référentielles
Se reporter à la section Utilisation des référentiels.
6.19.6. Transformations à base de script
6.19.6.1. Description
Un langage de script ouvert (Groovy [16]) permet d’accéder en lecture ou en écriture à l’ensemble des cellules d’un enregistrement.
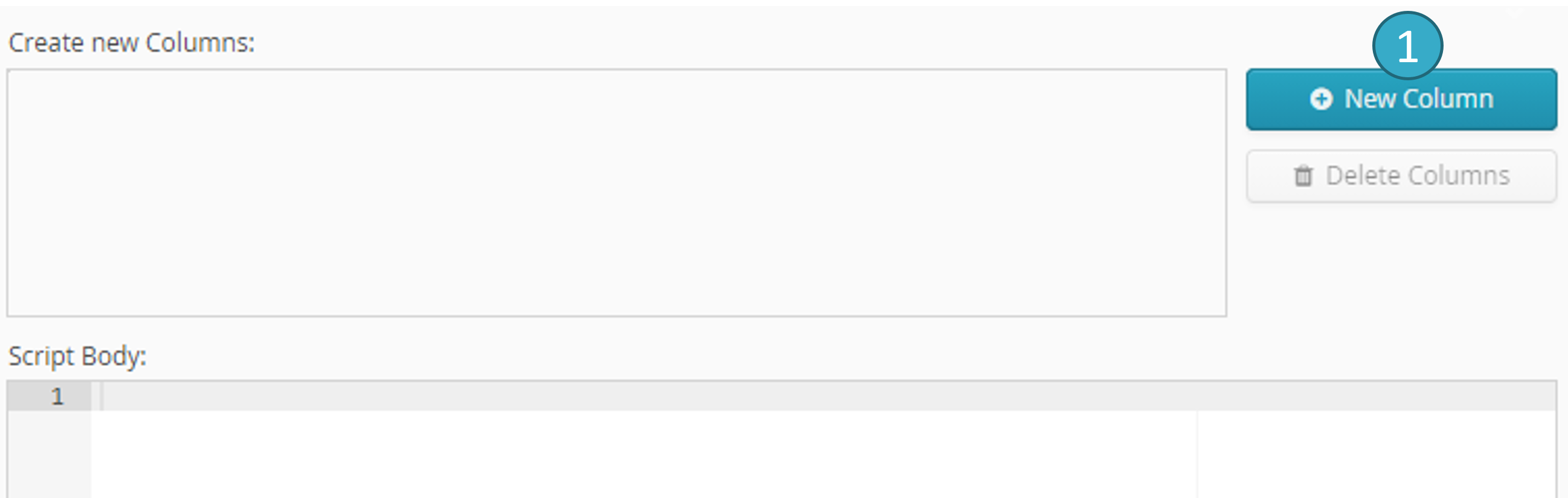
Il est possible de créer de nouveaux champs.
Pour cela cliquer sur le bouton « New Column » afin de spécifier le nom et le type du champ à ajouter :
Toutes les opérations arithmétiques de base sont disponibles ainsi que des centaines de fonctions pour manipuler du texte, des nombres ou des dates (le langage de script permet donc de créer des règles métier potentiellement complexes sur vos données).
L’intégralité de « Groovy » est accessible : boucles, structures de contrôles, manipulation des collections, création de variables, etc. (http://www.groovy-lang.org/groovy-dev-kit.html).
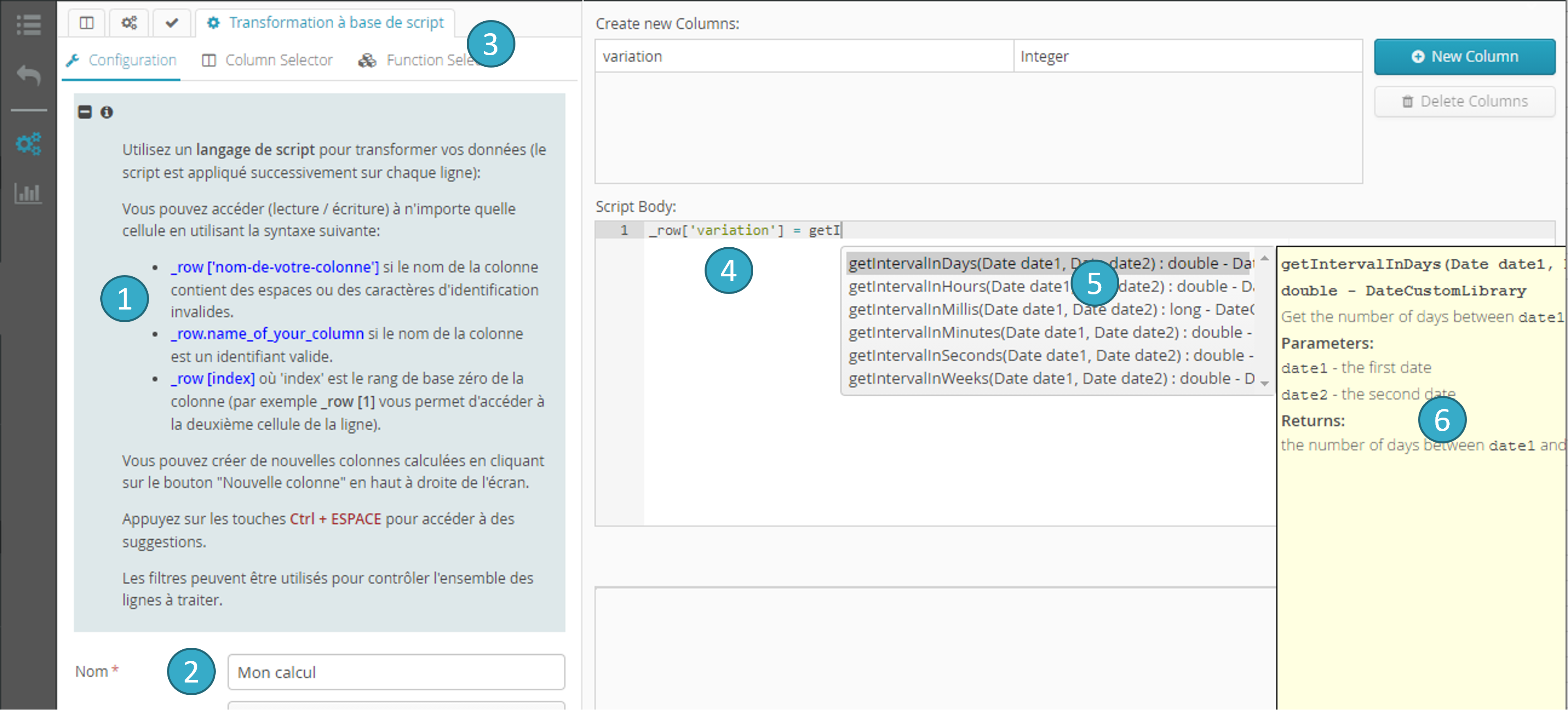
Zone d’aide
: vous y trouverez les informations de syntaxe pour lire, écrire dans des champs existants ou bien créer de nouveaux champs.Informations à fournir sur le script
: nom, commentaire, etc.Deux onglets supplémentaires
: un sélecteur de champs et un sélecteur de fonctions (plus de précision dans la suite de ce chapitre).Zone de saisie du texte de script
.Complétion automatique
(tapez Ctrl + Espace).Aide sur l’option de complétion sélectionnée
 .
.
6.19.6.2. Onglet Sélecteur de champs
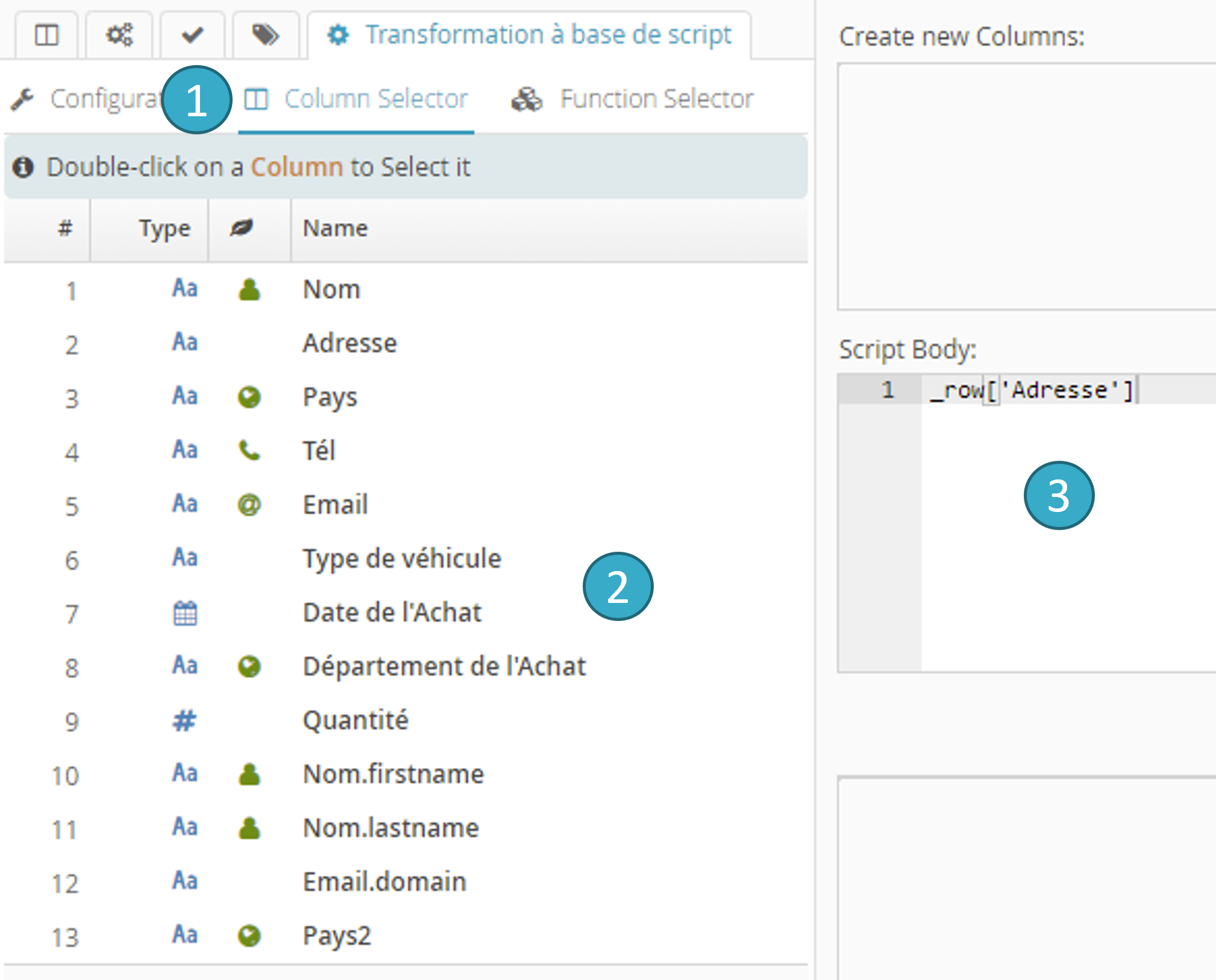
Sélectionner l’onglet Column Selector
.Double-cliquer sur un champ
.… pour l’injecter avec la syntaxe idoine dans la zone de script
.
6.19.6.3. Onglet Sélecteur de fonctions (alternative à la complétion automatique)
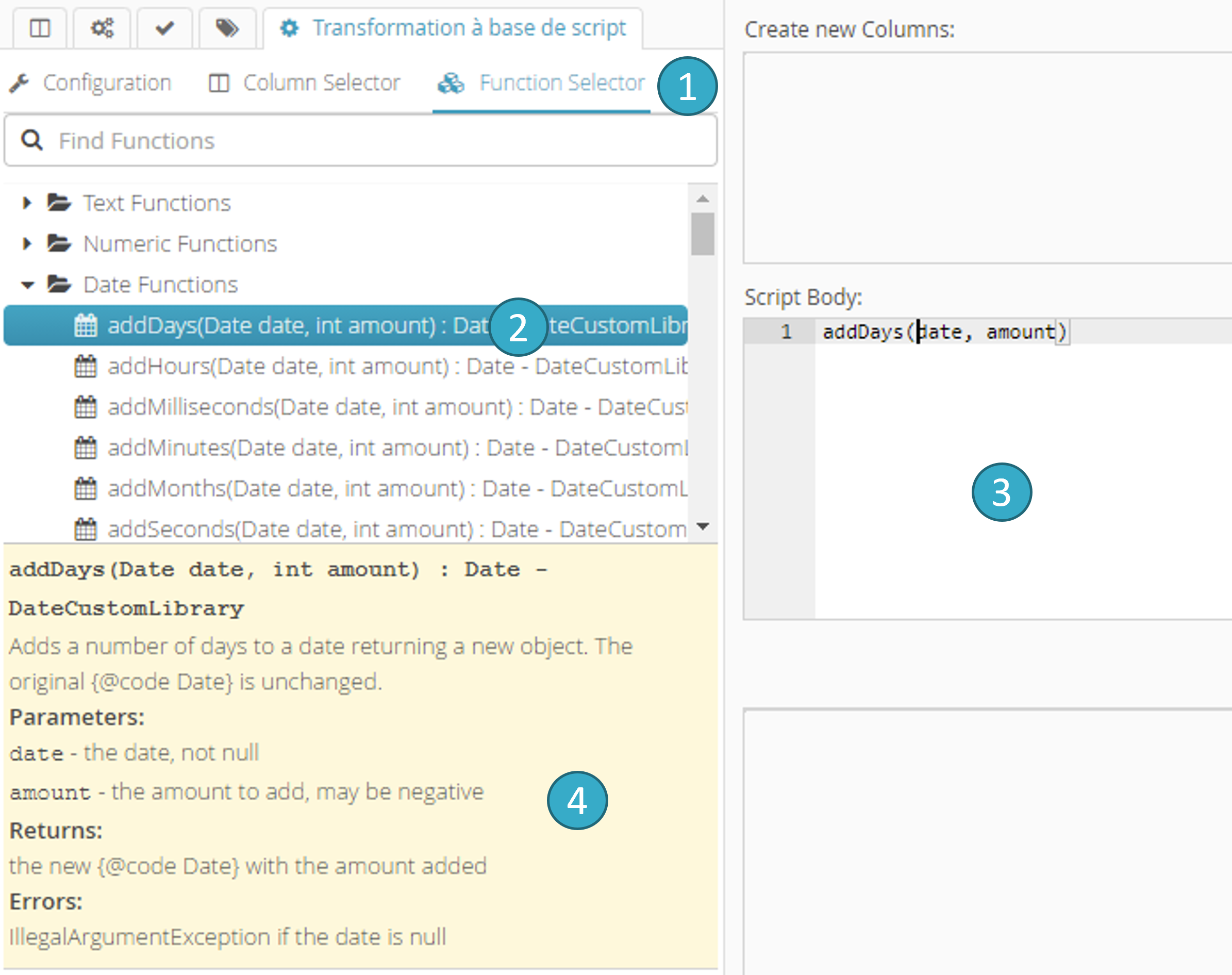
Sélectionner l’onglet Function Selector
.Double-cliquer sur une fonction
.… pour l’injecter avec la syntaxe idoine dans la zone de script
.Une aide
sur la fonction sélectionnée est disponible dans cette zone.
6.19.6.4. Validation de la syntaxe, Prévisualisation de l’exécution et Exécution
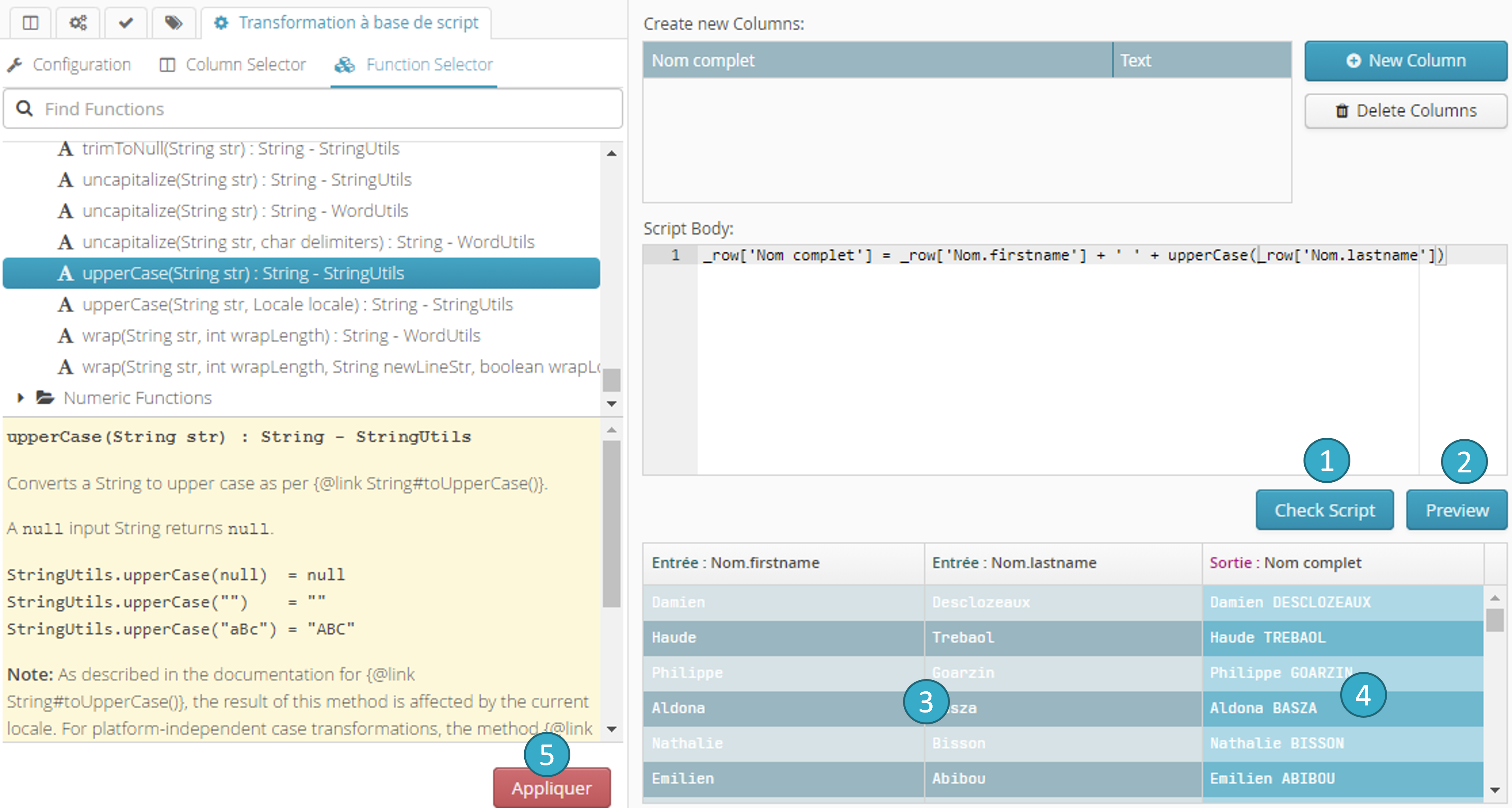
Cliquer sur le bouton Check Script
pour s’assurer de la validité de la syntaxe (indispensable pour pouvoir exécuter le script).Cliquer sur le bouton Preview
pour prévisualiser l’exécution du script (à ce stade la transformation de type « script » n’est toujours pas appliquée).Les zones en couleur
 de la table de prévisualisation montrent les champs dont la valeur est lue par le script.
de la table de prévisualisation montrent les champs dont la valeur est lue par le script.Les zones en couleur
 de la table de prévisualisation montrent les champs dont la valeur est modifiée par le script.
de la table de prévisualisation montrent les champs dont la valeur est modifiée par le script.Bouton Appliquer
: appliquer le script sur le jeu de données.
Exemple visuel :
Le script suivant crée un champ nommé C et affecte à ce champ la somme du contenu du champ A et du contenu du champ B :
\_row['C'] = \_row['A'] + \_row['B'] ou bien \_row.C = \_row.A + \_row.C
La seconde syntaxe n’est possible que lorsque les noms des champs ne contiennent pas d’espaces.
_rowest un mot réservé pour accéder à une cellule existante (en lecture ou en écriture).
La transformation s’applique sur un ou plusieurs champs.
La transformation utilise le ou les filtres actifs.
Note
Exemple pratique : Transformation à base de script
Avant Transformation :
ID |
Nom |
Ventes |
Région |
|---|---|---|---|
1 |
Alpha Co |
150 |
Nord |
2 |
Beta Inc |
200 |
Sud |
Configuration de la Transformation :
Nom : « Mon super script »
Langage du Script :
GroovyCommentaire : « Ceci est un script pour ajuster le montant des ventes selon la région. »
Annuler à la Première Erreur : si la transformation doit échouer dès la première erreur d’exécution du script rencontrée (par exemple, une division par zéro).
Nouvelles Colonnes : Aucune
Corps du Script :
if (record['Région'] == 'Nord') {
record['Ventes'] *= 1.1;
}
Après Transformation :
ID |
Nom |
Ventes |
Région |
|---|---|---|---|
1 |
Alpha Co |
165 |
Nord |
2 |
Beta Inc |
200 |
Sud |
Dans cet exemple, la transformation applique une augmentation de 10% sur les montants des ventes pour les enregistrements situés dans la région “Nord”, comme spécifié par le script basé sur Groovy. Les montants des ventes restent inchangés pour les autres régions. Cela montre comment la transformation peut appliquer des modifications sélectives en fonction des attributs du jeu de données, afin d’enrichir celui-ci selon la logique métier définie dans le script.
6.19.7. Transformation à la souris (Smart Select)
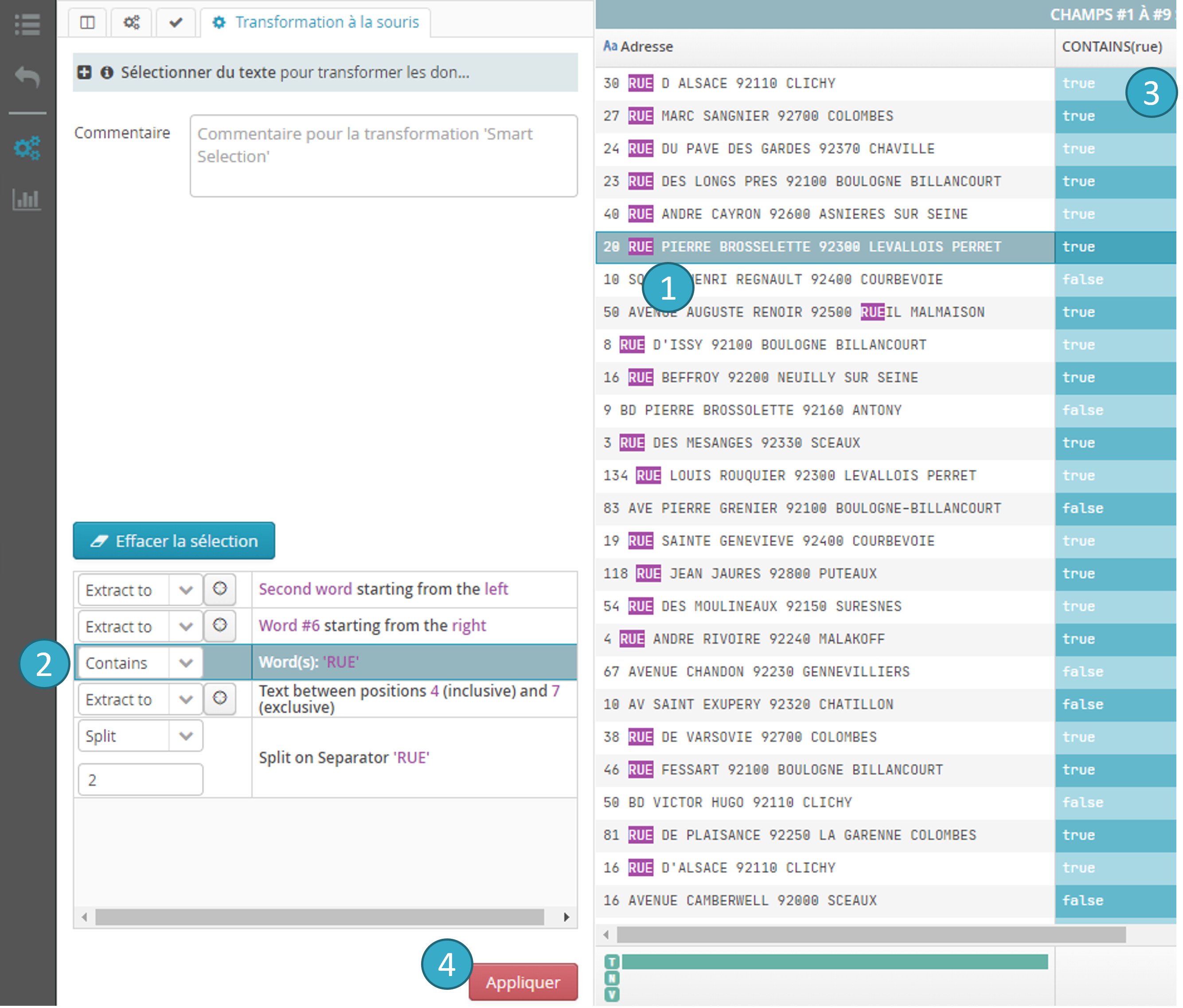
- Sélectionner un fragment de texte : faire un premier clic dans la cellule qui vous intéresse (bouton gauche de la souris, presser puis relâcher instantanément). Ensuite, une fois la cellule (et la ligne) sélectionnées faire glisser (drag) la souris en maintenant le bouton gauche pressé afin de sélectionner le texte qui vous intéresse.
- Tale of Data vous propose alors plusieurs options en fonction de la portion de texte que vous avez sélectionnée.
- Une ou plusieurs colonnes sur fond bleu apparaissent pour montrer quel serait le résultat de la transformation si vous décidiez de l’appliquer (prévisualisation).
Bouton Appliquer
: appliquer la transformation choisie.
Appelée aussi Smart Select, cette fonctionnalité permet, en sélectionnant tout ou partie du contenu d’une cellule, de laisser le système proposer une ou plusieurs actions possibles.
Exemple visuel :
En sélectionnant l’année d’une date, l’utilisateur se verra proposé d’extraire le nombre correspondant à l’année dans un nouveau champ.
En sélectionnant un caractère (e.g. ‘,” ou « ; », etc.), le système propose de séparer le contenu de la cellule sur plusieurs champs en utilisant comme séparateur le ou les caractères sélectionnés.
En sélectionnant un mot dans une phrase, le système propose de créer un champ indiquant si le mot est présent ou non dans la cellule (vrai / faux).
La transformation s’applique sur un unique champ.
La transformation utilise le ou les filtres actifs.
Note
Exemple pratique : Transformation à la souris
Avant Transformation :
ID |
Nom |
Statut |
Revenu |
|---|---|---|---|
1 |
Alpha Co |
Active |
150000 |
2 |
Beta Inc |
Inactive |
90000 |
3 |
Gamma LLC |
Active |
200000 |
Configuration de Transformation :
Sélection : Sélectionner le fragment de texte “Active” dans la colonne Statut.
Action : Valider la sélection et demander à ce que le fragment de texte « Active » soit remplacé par « Premium ».
Après Transformation :
ID |
Nom |
Statut |
Revenu |
|---|---|---|---|
1 |
Alpha Co |
Premium |
150000 |
2 |
Beta Inc |
Inactive |
90000 |
3 |
Gamma LLC |
Premium |
200000 |
6.19.8. Ajouter un indicateur de qualité
Créer un indicateur de qualité sur plusieurs critères : valeurs manquantes ou invalides, lignes invalides (violations de règles de validation de colonnes et / ou de lignes). Cette transformation peut être retrouvée dans la barre de recherche des transformations en utilisant le raccourci kpi.

- Choisir le nom de l’indicateur : ce nom sera utilisé pour créer la ou les colonnes qui contiendront les informations sur la qualité de chaque enregistrement (ligne).
- Choisir la méthode de calcul de l’indicateur. Six options sont proposées :
Booléen : “vrai” signifie qu’il y a un problème de qualité pour la ligne (au regard des types de contrôles spécifiés dans les zones tabulaires
et ).Booléen : “vrai” signifie qu’il n’y a aucun problème de qualité.
Entier (0 ou 1) : 1 signifie qu’il y a un problème de qualité.
Entier (0 or 1) : 1 signifie qu’il n’y a aucun problème de qualité.
Nombre de contrôles en échec (0 signifie OK). Pour chaque ligne, la valeur de l’indicateur correspond au nombre total d’échecs aux contrôle spécifiés dans les zones tabulaires
et .Nombre de contrôles en échec par type d’anomalies. Le calcul est identique au précédent, mais ici, 5 colonnes (une colonne par type d’anomalie) sont ajoutées en plus de la colonne total (qui porte le nom de l’indicateur) :
valeurs vides
valeurs mal formées (= échec de la vérification du type)
natures invalides (ex : téléphone ou email non valide)
valeurs ne respectant pas une règle de validation de colonne
enregistrement ne respectant pas une règle de validation de lignes
Nombre de contrôles en échec par colonne et par type d’anomalies. Le calcul est identique au précédent, mais ici, le résultat est trié par colonne :
valeurs vides
valeurs mal formées (= échec de la vérification du type)
natures invalides (ex : téléphone ou email non valide)
valeurs ne respectant pas une règle de validation de colonne
enregistrement ne respectant pas une règle de validation de lignes
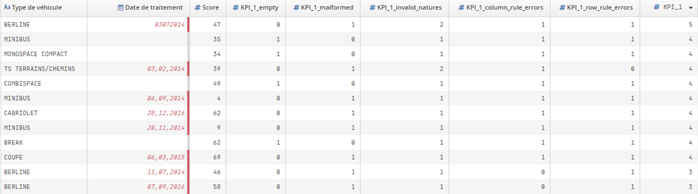
Méthode de calcul Nombre de contrôles en échec par type d’anomalies : six colonnes supplémentaires. Cinq colonnes sont préfixées par le nom de l’indicateur (KPI_1_XXX). La colonne portant le nom de l’indicateur contient le nombre total des anomalies pour une ligne donnée.
Deux types de contrôle peuvent être effectués pour le calcul de l’indicateur qualité :
Le contrôle par champ (onglet Règles de validation de champs
Une vérification du type :
dans un champ de type date par exemple, toutes les cellules contenant une valeur non reconnue comme une date valide seront considérées, dans le calcul de l’indicateur, comme étant en erreur.
Une vérification de la nature :
dans un champ identifié comme contenant des e-mails par exemple, toutes les cellules contenant une valeur non reconnue comme un e-mail valide seront considérées, dans le calcul de l’indicateur, comme étant en erreur.
Une vérification de la présence :
toutes les cellules ne contenant pas de valeur seront considérées, dans le calcul de l’indicateur, comme étant en erreur.
- Une vérification des règles de validation de champ apposée dans un nœud de préparation en amont.
Dans le champ spécifié, toutes les cellules contenant une valeur non valide au sens de la règle (ex : liste de valeurs admises ou intervalle de validité) seront considérées, dans le calcul de l’indicateur, comme étant en erreur.
Le contrôle par enregistrement (onglet « Règles de validation de lignes »
Note
Exemple pratique : Ajouter un indicateur de qualité
Avant la transformation :
ID |
Nom |
Âge |
|
|---|---|---|---|
1 |
Alice |
30 |
|
2 |
Bob |
||
3 |
Charlie |
25 |
N/A |
Configuration de la transformation :
Nom de l’indicateur : « MyKPI »
Vérifications de qualité :
Vérification des champs vides
Validation des types de données
Exactitude de la nature des données
Méthode de calcul de l’indicateur :
Nombre d’échecs de contrôle par type d’anomalie
Après la transformation :
ID |
Nom |
Âge |
MyKPI__vide |
MyKPI__malformé |
MyKPI__natures_invalides |
MyKPI |
|
|---|---|---|---|---|---|---|---|
1 |
Alice |
30 |
0 |
0 |
0 |
0 |
|
2 |
1 |
1 |
1 |
3 |
|||
3 |
Charlie |
25 |
0 |
0 |
1 |
1 |
Dans cet exemple, la transformation ajoute quatre nouvelles colonnes :
MyKPI__vide: nombre total de valeurs manquantes pour la ligne.MyKPI__malformé: nombre total d’erreurs de reconnaissance de type.MyKPI__natures_invalides: nombre total d’erreurs de reconnaissance de nature.MyKPI: total général des erreurs pour la ligne.
Explication pour la ligne 2 (Bob) :
Le nom de Bob est manquant →
MyKPI__vide = 1L’âge est malformé (un tiret au lieu d’un nombre) →
MyKPI__malformé = 1L’adresse email est invalide (« Bob@xx » n’est pas un email valide) →
MyKPI__natures_invalides = 1Total général des erreurs (colonne
MyKPI) : 1 + 1 + 1 = 3