11.5. Exploitation des résultats d’une analyse
11.5.1. Différentes manières d’exploiter les résultats
Une fois qu’une analyse a été configurée, lancée et s’est terminée, le but sera d’en exploiter les résultats.
Ceci peut se faire de plusieurs manières différentes:
avec les données brutes qui auront été exportées (voir section ici pour la configuration de l’export), il sera possible:
d’en faire l’exploitation à l’aide de flows et/ou de tableaux de bords, que ce soit avec un lancement manuel de flows ou de séquences de flows, ultérieurement, à la convenance des utilisateurs, ou en programmant l’exécution d’un flow ou d’une séquence de flows automatiquement dès que l’analyse est terminée.
d’intégrer dans d’autres outils (par exemple Data Catalog tiers, MDM, …) ces données brutes, en utilisant la data comme interface d’échange et d’enrichissement. En effet ces données brutes peuvent être écrites dans n’importe quel système présent dans le catalogue, et pourront donc facilement être lues par ces systèmes tiers qui se verront enrichis avec des métadonnées qualité très pertinentes pour la connaissance des systèmes.
Note
Pour plus d’informations sur la structure des données brutes qui sont générées lorsque l’export est activé, voir la section correspondante.
avec l’interface graphique, il est possible d’accomplir les tâches suivantes:
visualiser les résultats d’analyse, à l’échelle d’une source de données complète provenant du catalogue, ou d’un groupe de tables pour des bases de données, ou un dossier particulier pour des systèmes fichiers, ou une table particulière (drill-down).
regarder visuellement l’évolution de la masse de données au cours du temps, en regardant l’évolution des résultats d’analyse pour le système sélectionné.
exporter en une fiche descriptive PDF ou un classeur excel les résultats d’analyse pour le système sélectionné.
observer les statistiques avancées pour la table sélectionnée, si il existe des résultats d’analyse pour lesquelles leur calcul a été demandé.
Nous commençons dans les sections suivantes par la description de l’utilisation de l’interface graphique de visualisation des résultats.
11.5.2. Statistiques globales
La vue actualisée de la cartographie des anomalies prend en compte les derniers résultats d’analyses.
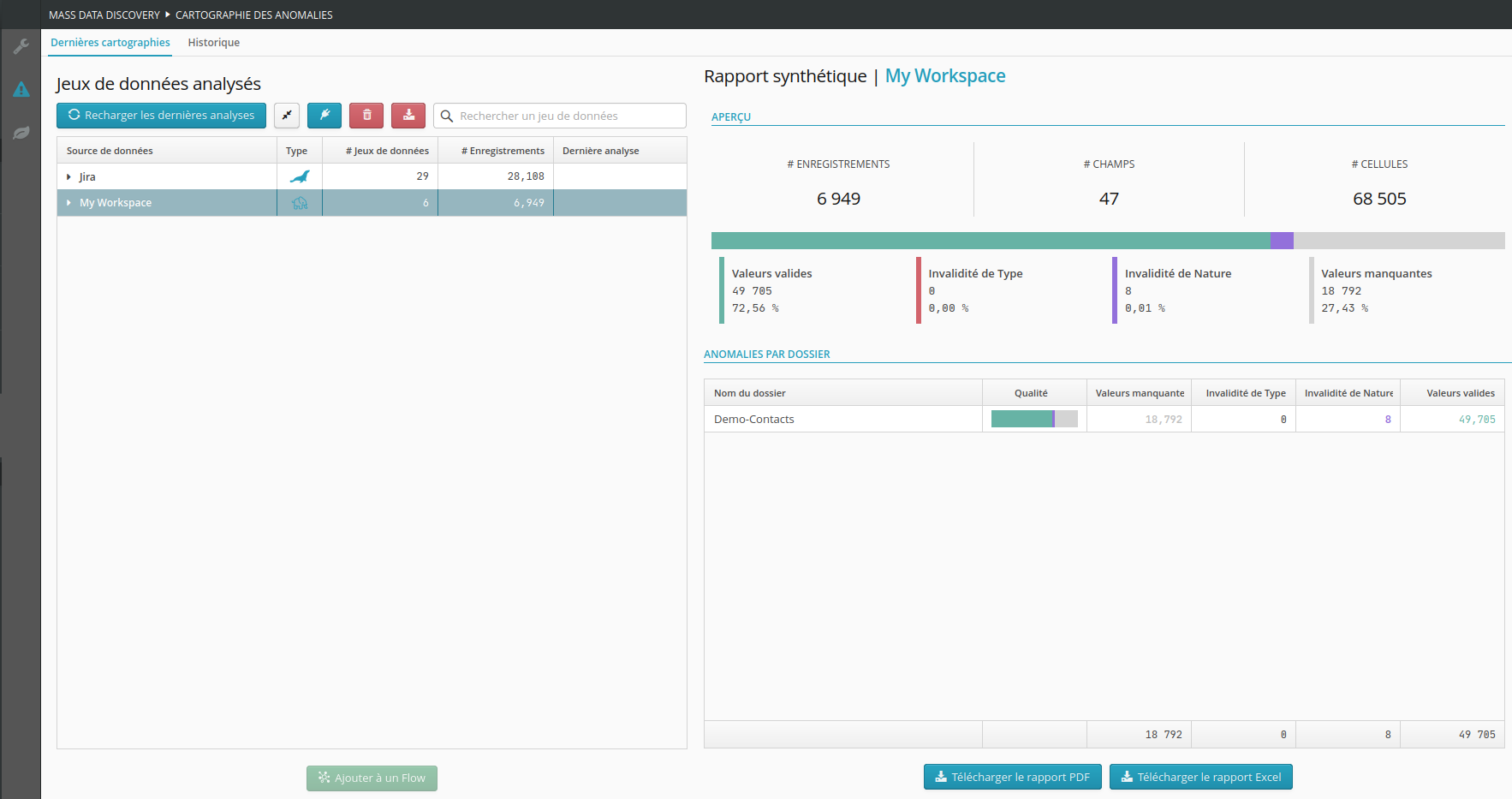
Les résultats précédemment consolidés sont ici présentés de manière adaptée à des besoins en rapport avec le typage des données :
Vue instantanée de la cartographie des anomalies.
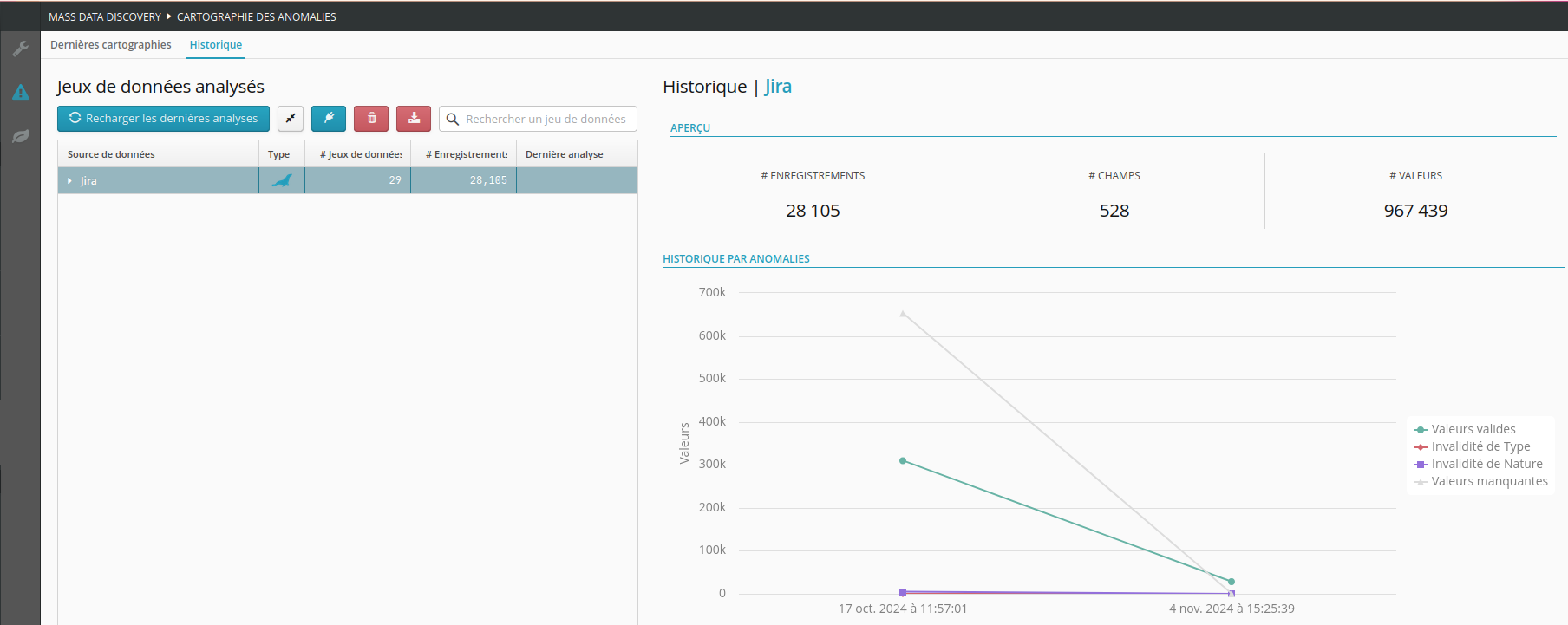
Vue historique de l’évolution des anomalies.
Rapports PDF.
Rapports Excel pour des exploitations externes.
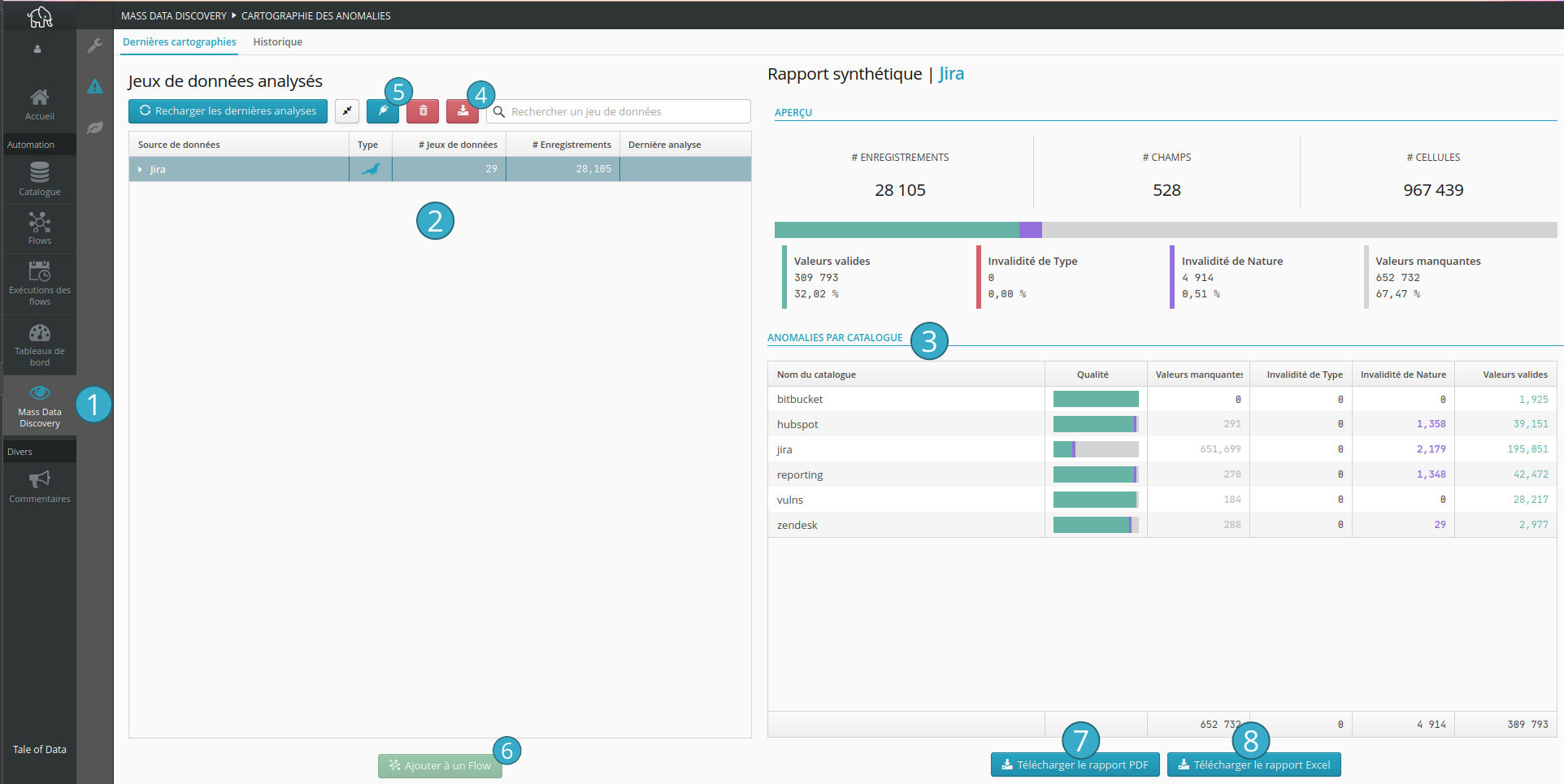
Bouton permettant d’accéder à l’écran du Mass Data Discovery
 .
.Zone présentant une vue d’ensemble des anomalies par source de données et jeu de données
 .
.Zone présentant une vue synthétique des anomalies en fonction de la source de données ou du jeu de données sélectionné : les données des sous-éléments sont agrégées au niveau de l’élément sélectionné
 .
.Bouton permettant d’ajouter une source de données.

Bouton permettant de créer un flow à partir du jeu de données sélectionné.

Bouton permettant de télécharger la liste des erreurs de la dernière analyse pour la source de données sélectionnée.

Bouton permettant de télécharger le rapport synthétique de la cartographie des anomalies au format PDF (les données dépendent de l’élément sélectionné dans l’arbre de gauche)
 .
.Bouton permettant de télécharger les données brutes de la cartographie des anomalies au format Excel (les données dépendent de l’élément sélectionné dans l’arbre de gauche)
 .
.
L’Historique est aussi accessible à partir du second onglet. Ceci étant afin de voir l’évolution de la cartographie des anomalies par analyse effectuée dans le temps pour le jeu de données sélectionné.
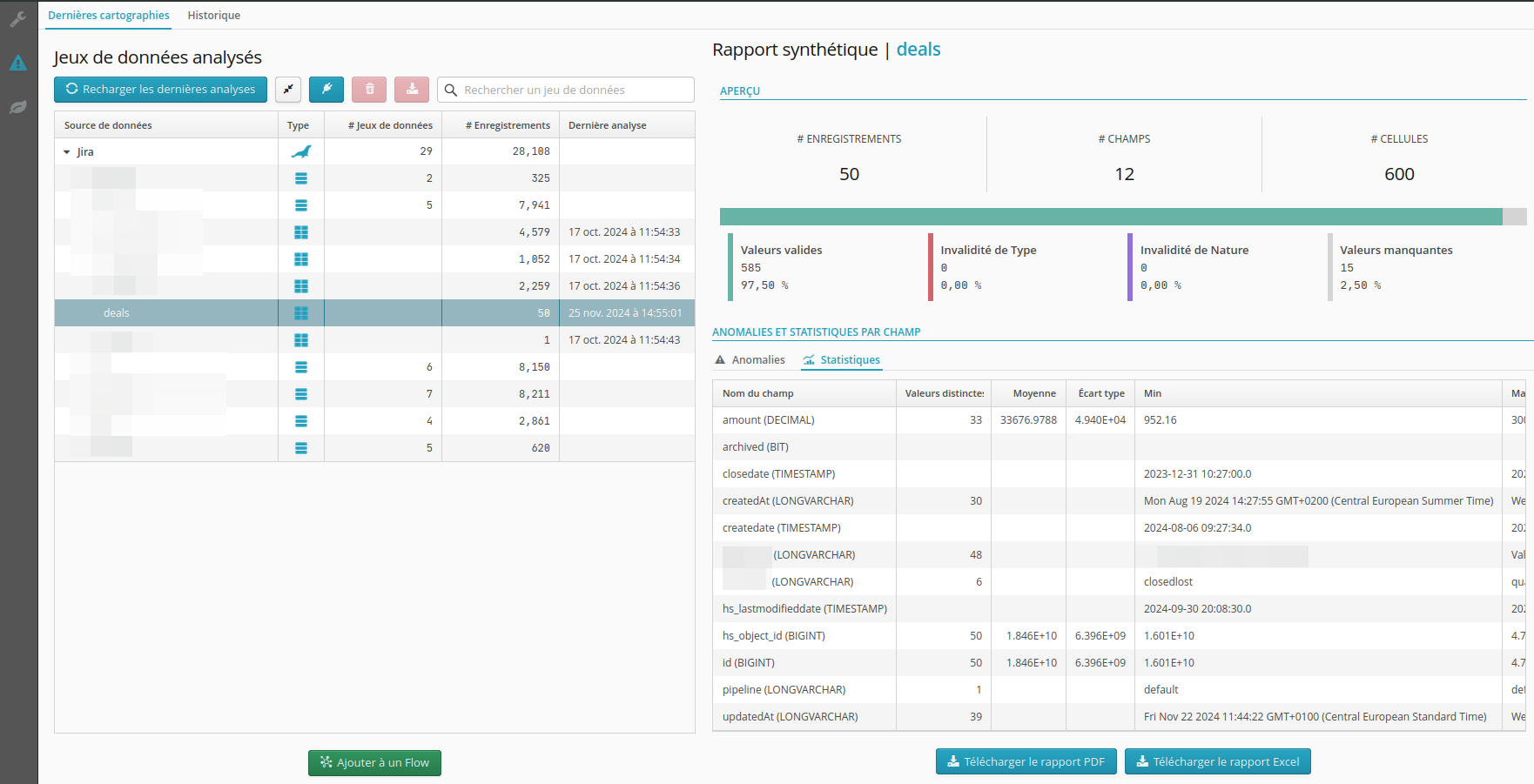
11.5.3. Statistiques avancées
Si l’option pour charger des statistiques avancées a précédemment été sélectionné, le résultat du calcul des valeurs distinctes sera alors affichés dans un onglet statistiques avancées sous anomalies et statistiques par champs.
11.5.4. Analyse sémantique des données
La vue actualisée de la cartographie des natures prend en compte les derniers résultats d’analyses. Par conséquent, seuls les champs avec une nature sont ici affichés.
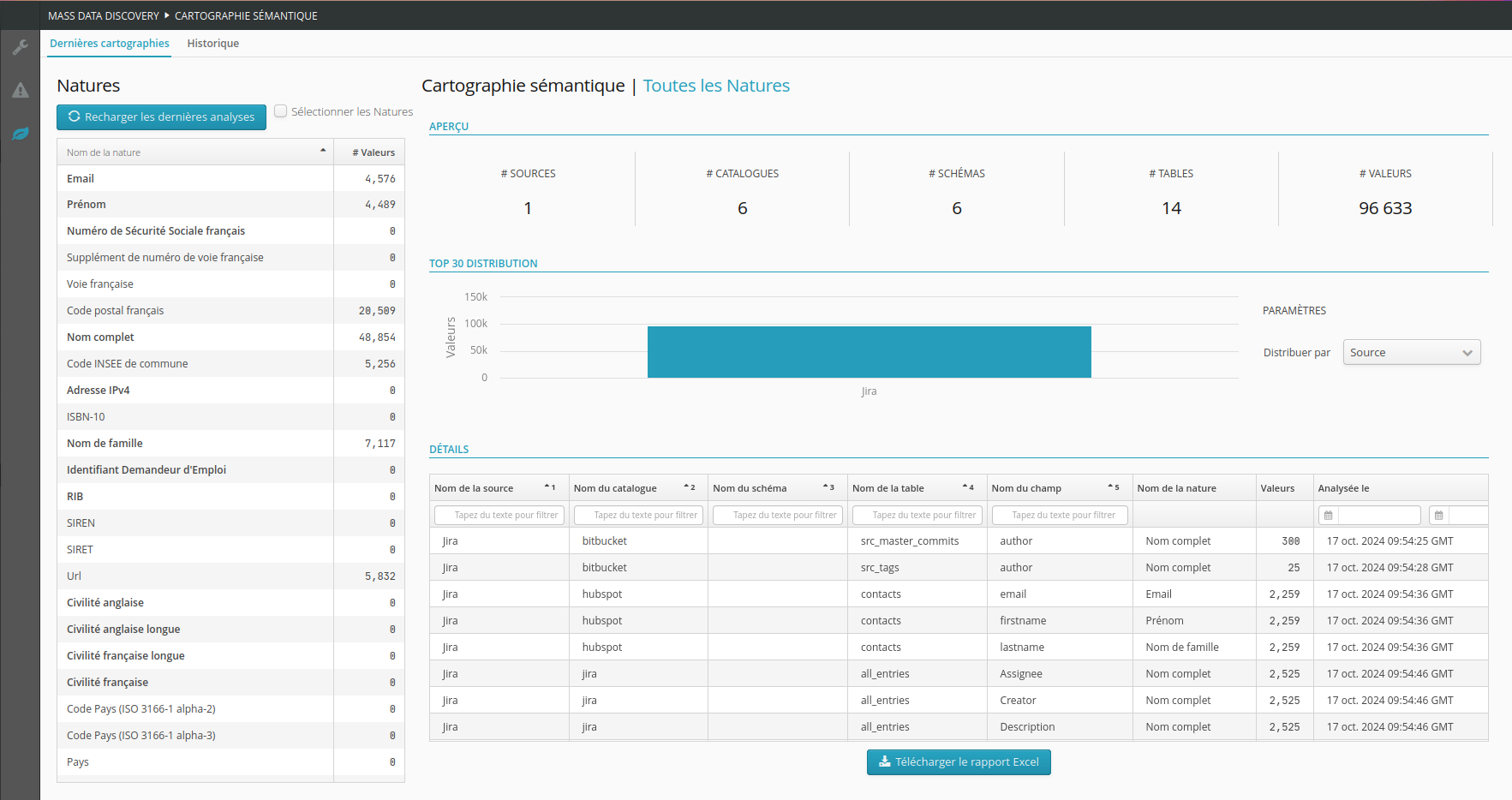
Les résultats précédemment consolidés sont ici présenter de manière adaptée à des besoins en rapport avec la nature des données :
Vue instantanée de la cartographie des natures.
Vue historique de l’évolution des natures.
Rapports PDF.
Rapports Excel pour des exploitations externes.
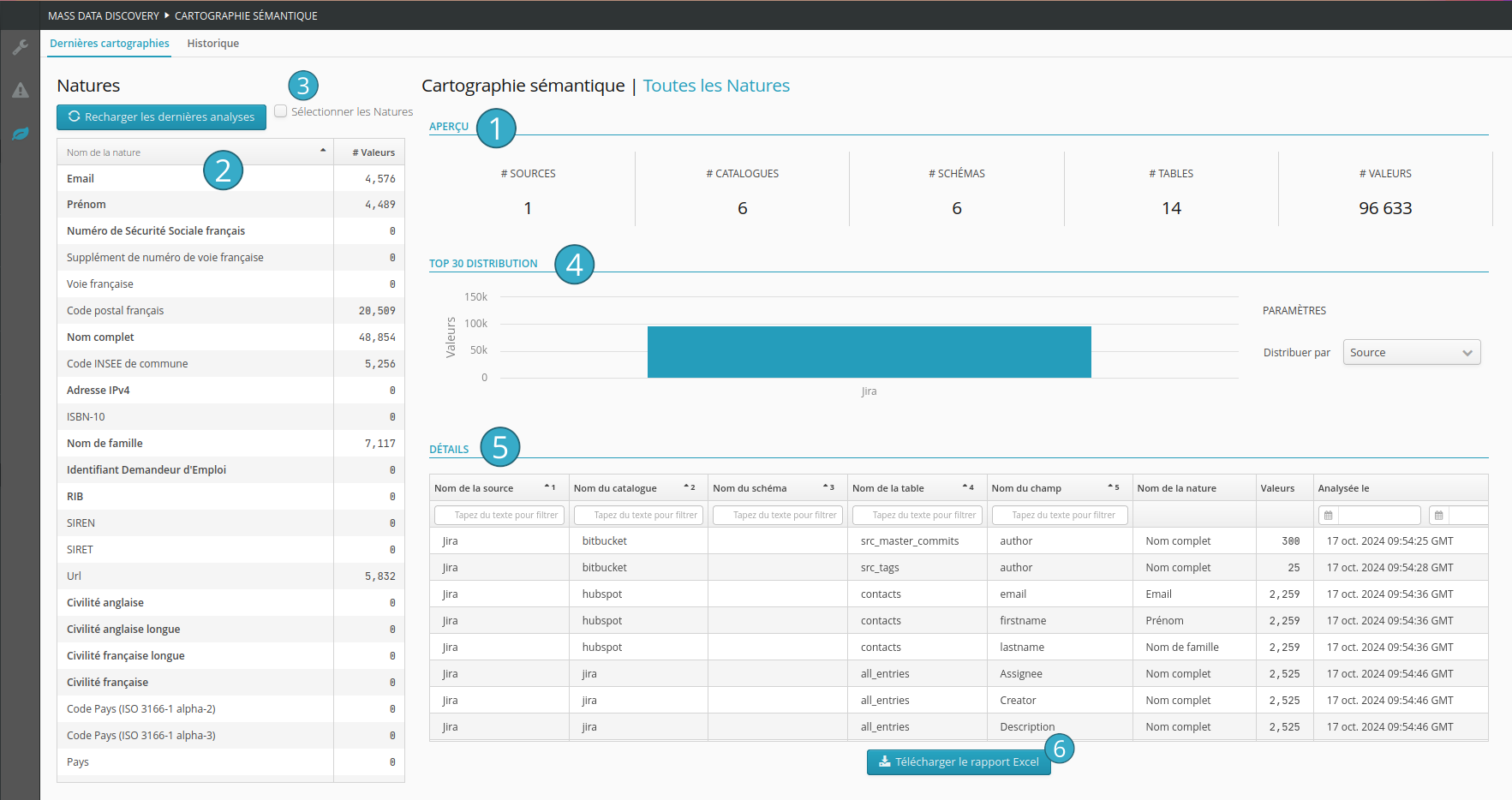
Zone présentant un aperçu du nombre de source de données, de catalogues, de schémas, de tables et de valeurs présentes dans la cartographie des natures sélectionnée
. En l’absence de sélection, l’ensemble des résultats ayant une nature (RGPD et autres) est affiché.Zone présentant l’ensemble des natures. En gras les natures dites RGPD (données à caractère personnel)
. La sélection d’un ou plusieurs éléments permet de filtrer les résultats (partie droite de l’écran).Bouton permettant de sélectionner / désélectionner directement les natures dites RGPD
.Zone présentant le nombre de valeurs pour les natures sélectionnées, réparti par source de données
. En l’absence de sélection, l’ensemble des résultats ayant une nature est affiché.Zone présentant le détail de la cartographie des natures par champ
. Seuls les champs ayant des natures sont affichés.Bouton permettant de télécharger les données brutes de la cartographie des natures au format Excel (les données dépendent de l’élément sélectionné dans la table de gauche)
.
L’Historique est aussi accessible à partir du second onglet. Ceci étant afin de voir l’évolution de la cartographie des natures par analyse effectuée dans le temps pour le jeu de données sélectionné. Seuls les champs avec une nature sont donc affichés.

11.5.5. Exploitation des données brutes des analyses
Dans l’onglet Exécutions des analyses, il est possible d’accéder directement au résultat situé dans le catalogue avec le raccourci Ouvrir.

Ces données brutes peuvent être exploitées au travers de flows dans ToD à des fins par exemple de monitoring, de transformation ou de reporting. Son format ToD facilite également l’exploitation à travers d’autres outils (data catalogue, MDM, etc…).
Nous détaillons ci-dessous la structure des champs exportés par le MDD, une fois une analyse de ces données brutes effectuée ( voir le screen suivant ).

Chaque colonne, de chaque table, est décrite par une ligne dans l’export des données.
Astuce
Les champs concernés par les statistiques avancées ne seront remplis que si l’option de calculer celles-ci a été activée. Dans le cas contraire, les cellules correspondantes seront vides mais néanmoins présentes dans les résultats bruts de l’analyse.
11.5.5.1. Détails sur l’analyse et la table étudiée
- job_run_identifier
un UUID identifiant le run de l’analyse; sera le même pour toutes les colonnes scannées au sein d’un même run
- analysis_uuid
UUID de l’analyse concernée; sera la même indépendamment du moment du run
- dataset
Nom de la table sélectionnée
- path
Nom du chemin où se trouve la table
- job_start_date_time_utc
Heure de départ du processeur lancé
- analysis_date_time_utc
Heure de départ de l’analyse exécutée
- data_store_name
Nom de la source de donnée, d’où provient le catalogue et la table
- data_store_type
Type de DMS de la source de donnée
- catalog_name
Nom du catalogue
- catalog_type
Type de catalogue
- schema_name
Nom du fichier sélectionné à l’intérieur du catalogue en question, le schéma de la base de donnée
- schema_type
Le type du schema sélectionné ( fichier ou autre )
- schema_sub_type
Le format du schema sélectionné ( ex: CSV, si fichier CSV)
- table_name
Le nom de la table, soit le nom du dataset ( sans extension )
- table_type
Le type de la table, soit TABLE ( si dataset )
11.5.5.2. Détails sur chaque colonne de la table
- field_name
Le nom de la colonne identifiée
- field_type
Le type de la colonne identifiée
- nature
La nature de la colonne identifiée
- cells_count
Le nombre de cellules non-vides dans la colonne identifiée
- blank_cells_count
Le nombre de cellules vides dans la colonne identifiée
- blank_cells_percent
Le pourcentage de cellules vides par rapport à l’ensemble des cellules
- invalid_type_cells_count
Le nombre de cellules de types invalides dans la colonne identifiée
- invalid_type_cells_percent
Le pourcentage de cellules de types invalides par rapport à l’ensemble des cellules
- invalid_nature_cells_count
Le nombre de cellules de natures invalides dans la colonne identifiée
- invalid_nature_cells_percent
Le pourcentage de cellules de natures invalides par rapport à l’ensemble des cellules
- invalid_type_samples
Exemple de type de invalide
- invalid_nature_samples
Exemple de nature de invalide
11.5.5.3. Statistiques avancées sur chaque colonne
Les colonnes suivantes seront produites si l’option statistiques avancées a été paramétrée pour l’analyse.
- count_distinct
Compte du nombre de valeurs distinctes dans la colonne
- mean
Calcul de la valeur moyenne pour les colonnes numériques
- stddev
Calcul de la déviation standard ( variation ou dispersion ) des valeurs pour les colonnes numériques
- min
Valeur minimale de la colonne
- percentile_5
Calcul du pourcentile 5 pour les colonnes numériques, en-dessous duquel 5% des observations tombent
- percentile_25
Calcul du pourcentile 25 pour les colonnes numériques, en-dessous duquel 25% des observations tombent
- percentile_50
Calcul du pourcentile 50 pour les colonnes numériques, en-dessous duquel 50% des observations tombent
- percentile_75
Calcul du pourcentile 75 pour les colonnes numériques, en-dessous duquel 75% des observations tombent
- percentile_95
Calcul du pourcentile 95 pour les colonnes numériques, en-dessous duquel 95% des observations tombent
- max
Valeur maximale de la colonne