Group duplicate entries by creating a lookup key
- Problem Description:
How can seemingly duplicate names be identified in my database?
Solution:
The ‘multi-algorithm deduplication’ feature is accessible in the preparation editor of a flow:
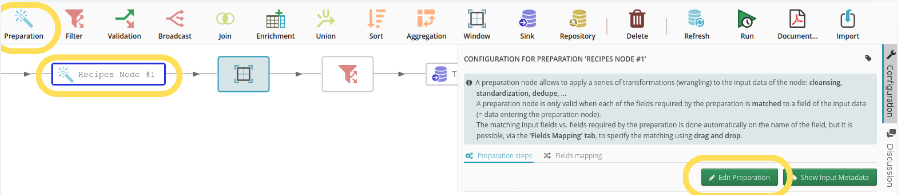
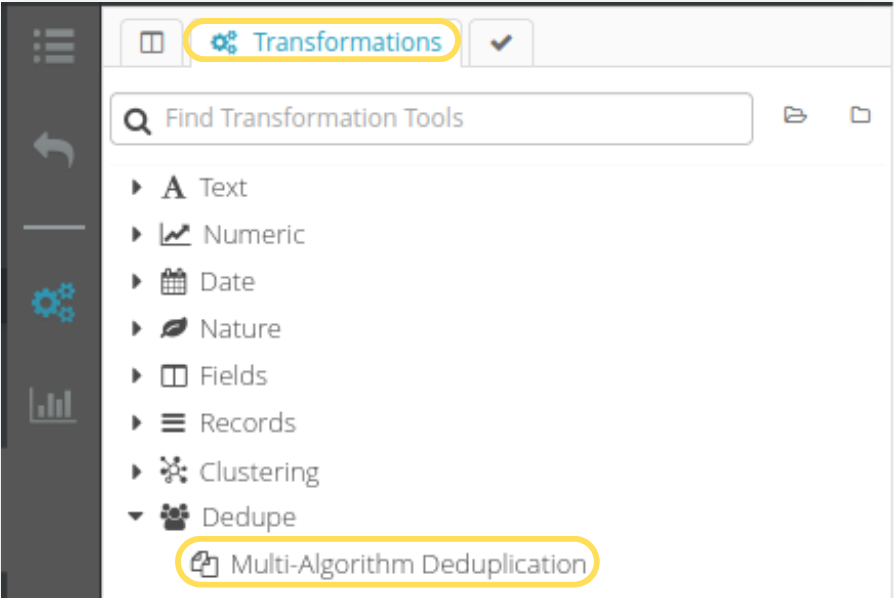
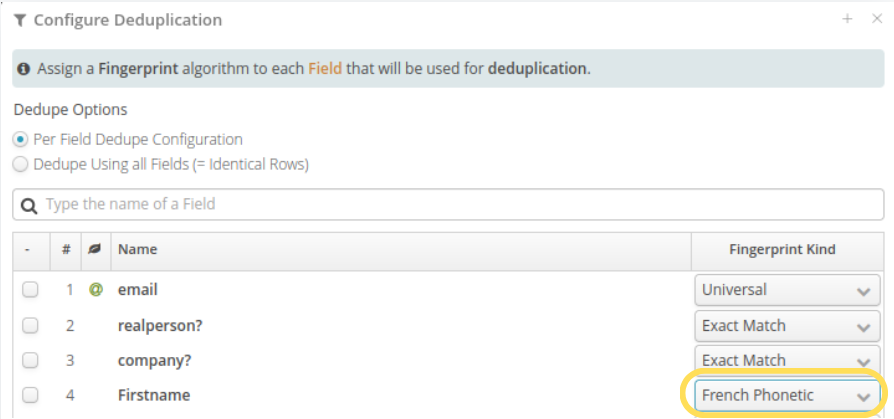
Two areas need to be configured:
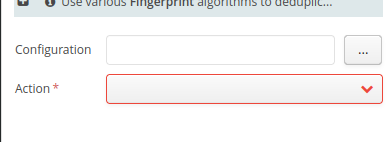
For this example, we will group by first name using the French phonetics algorithm, because that is the best one for the data we are considering, but other algorithms are also available. It is possible as well to group into a single key multiple columns simultaneously, even assigning a different algorithm for each column.
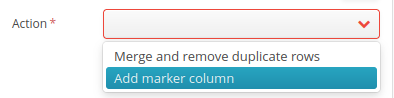
The second area, “Action”, has two options:
Merge and remove duplicate rows : Delete identical rows based on the checkboxes selected in the previous step and keep only one instance (any one) per present type.
Add marker column : Add a column with a marker (fingerprint)
In our case, we want the second option. The new column with a marker now looks like this:
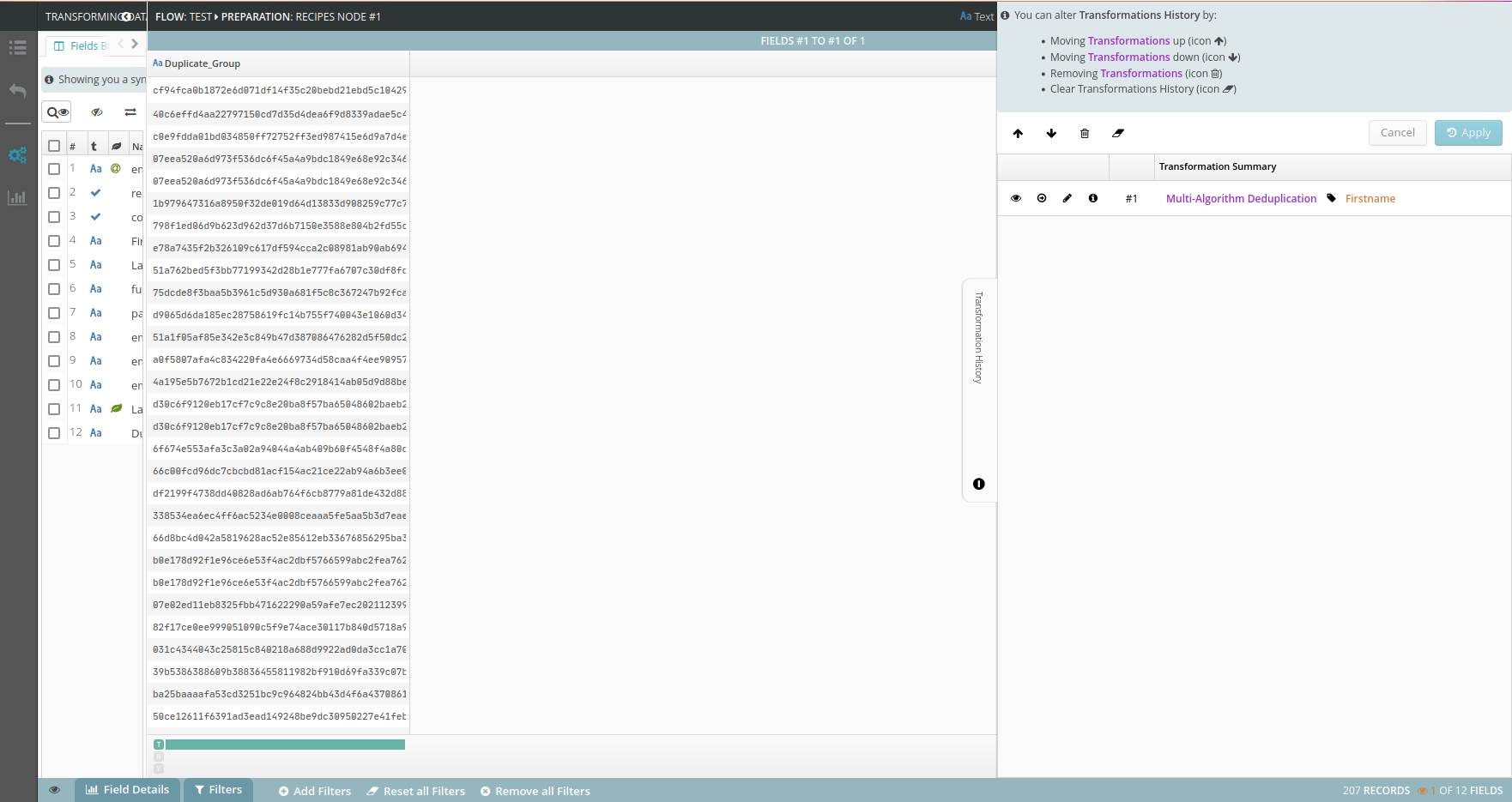
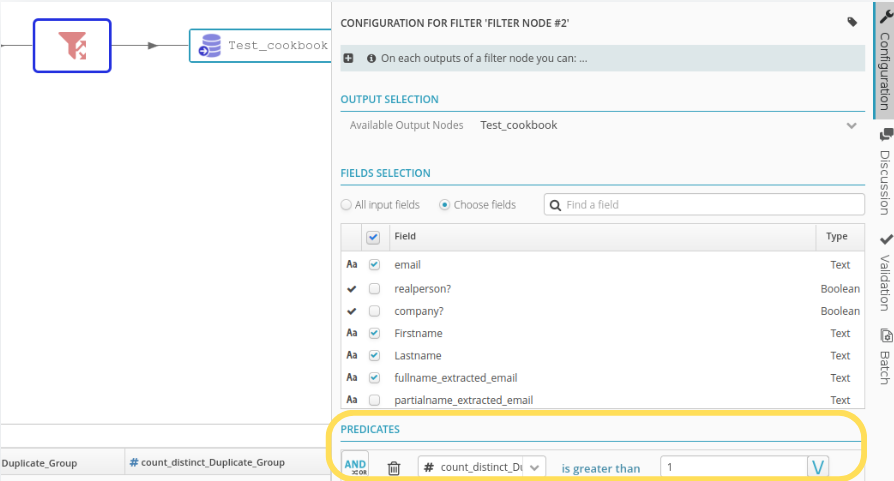
The second step now is to use a window function to partition on the fingerprint and count the number of markers (i.e., the number of rows) in the window.
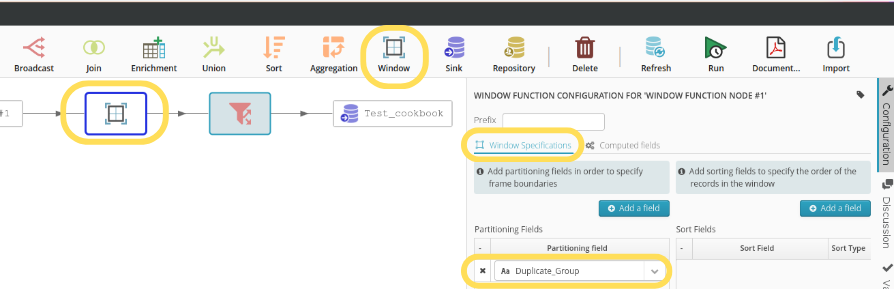
Finally, the filter function can now be used to examine counts greater than 1, in order to identify duplicates and decide if the generated grouping is acceptable or not.