Créer une clé pour regrouper les doublons
- Description du Problème :
Comment identifier des noms qui semblent être en double dans ma base de données ?
Solution :
La fonctionnalité “dédoublonnage multi-algorithmes” figure dans l’éditeur de préparation d’un flow:
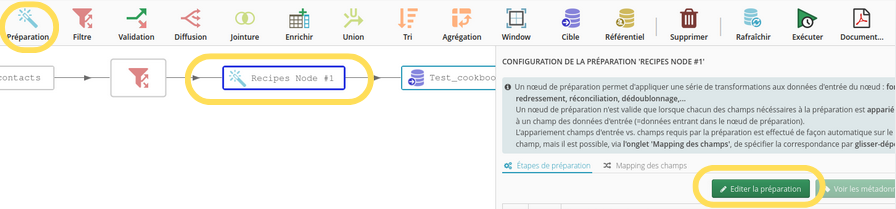
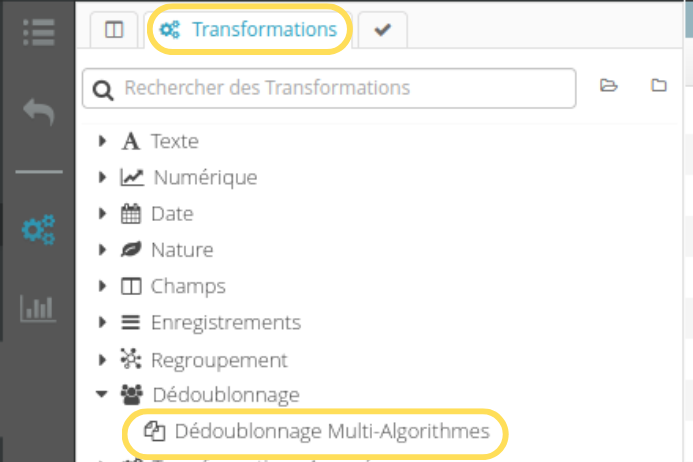
Deux zones sont à configurer:
Pour notre exemple, nous allons effectuer un regroupement sur le prénom par phonétique française, mais d’autres algorithmes sont aussi possibles. Il est également possible de faire le regroupement en prenant en compte plusieurs colonnes simultanément, éventuellement avec différents algorithmes pour chaque colonne.
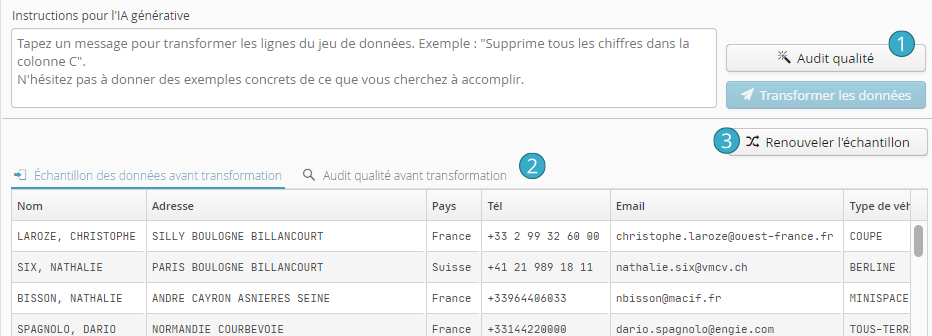
La deuxième zone « Action » possède deux options:
Merge and remove duplicate rows : Supprimer les lignes identiques en fonction des cases cochées à l’étape précédente et ne garder qu’un exemplaire (n’importe lequel) par type présent.
Add marker column : Ajouter une colonne avec un marqueur (fingerprint)
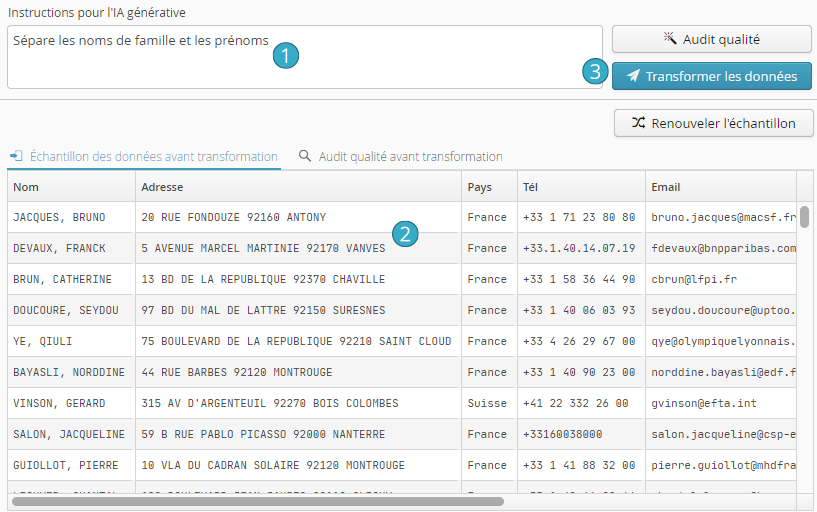
Dans notre cas, nous souhaitons la deuxième option. La nouvelle colonne avec un marqueur ressemble maintenant à ceci :
La deuxième étape consiste maintenant à utiliser une fonction de fenêtre afin de partitionner sur le fingerprint et de compter le nombre de marqueurs (c’est-à-dire le nombre de lignes) dans la fenêtre.
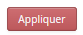
Enfin, la fonction filtre peut à présent être utiliser pour examiner les décomptes supérieurs à 1, afin d’identifier les doublons et de décider si le regroupement généré est acceptable ou non.